Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-weave-caching.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Weave を使用したモデルの評価
W&B Weave は、LLM および GenAI アプリケーションを評価するために構築された専用のツールキットです。scorer、judge、詳細なトレースなど、包括的な評価機能を提供し、モデルのパフォーマンスを理解して向上させるのに役立ちます。Weave は W&B Models と統合されており、モデルレジストリ に保存されているモデルを評価することができます。
モデル評価の主な機能
- Scorer と Judge: 正確性、関連性、コヒーレンスなどのための、事前定義済みおよびカスタムの評価メトリクス
- 評価用データセット: 体系的な評価のための正解(ground truth)を含む構造化されたテストセット
- モデルのバージョン管理: 異なるバージョンのモデルを追跡して比較
- 詳細なトレース: 完全な入力/出力トレースによりモデルの振る舞いをデバッグ
- コスト追跡: 評価全体での API コストとトークン使用量を監視
はじめに:W&B Registry からモデルを評価する
W&B Models Registry からモデルをダウンロードし、Weave を使用して評価します。
import weave
import wandb
from typing import Any
# Weave を初期化
weave.init("your-entity/your-project")
# W&B Registry からロードする ChatModel を定義
class ChatModel(weave.Model):
model_name: str
def model_post_init(self, __context):
# W&B Models Registry からモデルをダウンロード
with wandb.init(project="your-project", job_type="model_download") as run:
artifact = run.use_artifact(self.model_name)
self.model_path = artifact.download()
# ここでモデルを初期化
@weave.op()
async def predict(self, query: str) -> str:
# モデルの推論ロジック
return self.model.generate(query)
# 評価用データセットを作成
dataset = weave.Dataset(name="eval_dataset", rows=[
{"input": "フランスの首都は?", "expected": "パリ"},
{"input": "2+2は?", "expected": "4"},
])
# scorer を定義
@weave.op()
def exact_match_scorer(expected: str, output: str) -> dict:
return {"correct": expected.lower() == output.lower()}
# 評価を実行
model = ChatModel(model_name="wandb-entity/registry-name/model:version")
evaluation = weave.Evaluation(
dataset=dataset,
scorers=[exact_match_scorer]
)
results = await evaluation.evaluate(model)
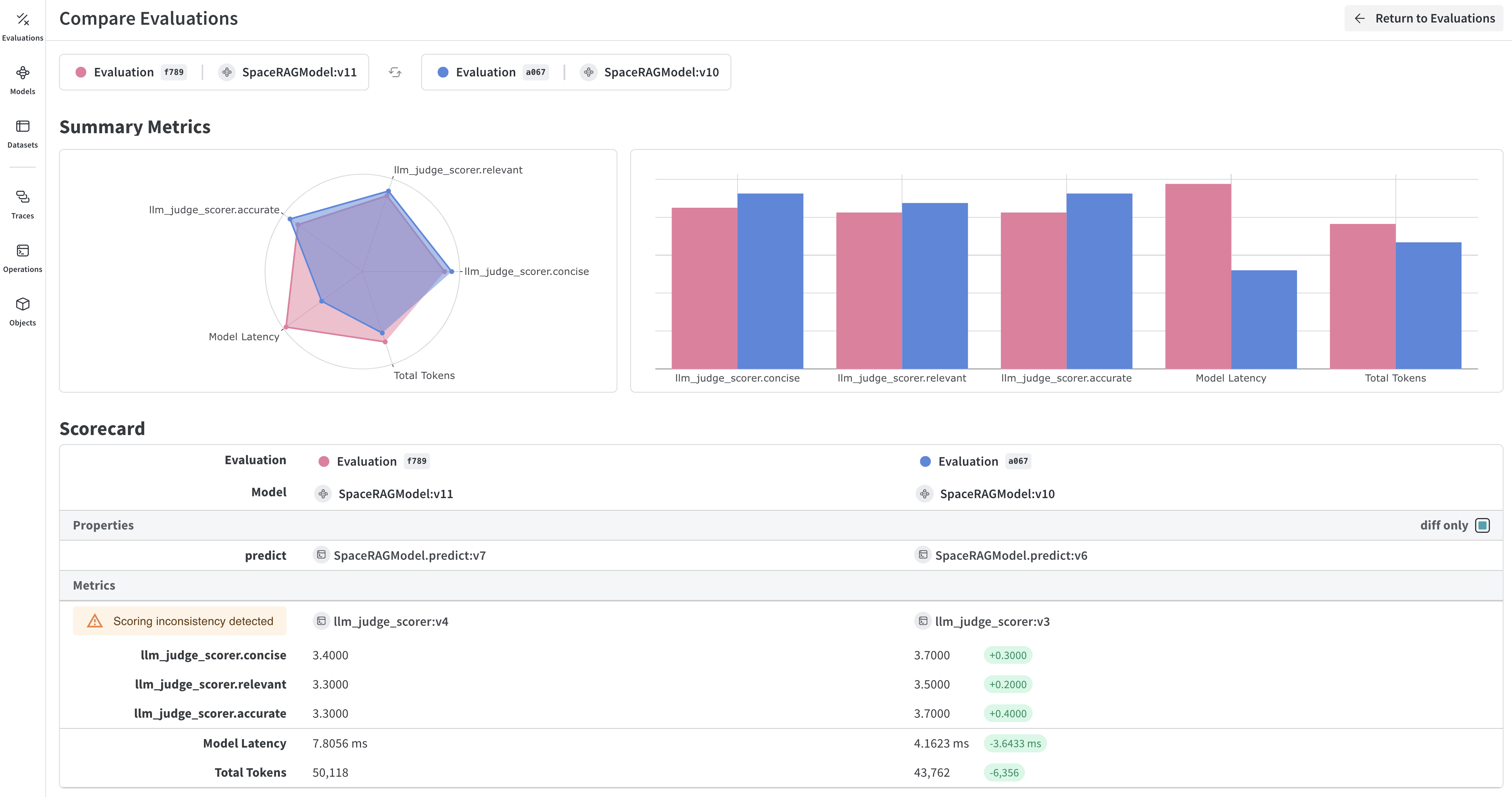
Weave の評価を W&B Models と統合する
Models and Weave Integration Demo では、以下の完全なワークフローを紹介しています:
- Registry からモデルをロード: W&B Models Registry に保存されたファインチューン済みモデルをダウンロード
- 評価パイプラインの作成: カスタム scorer を使用した包括的な評価を構築
- 結果を W&B にログ記録: 評価メトリクスをモデルの Runs に接続
- 評価済みモデルのバージョン管理: 改善されたモデルを Registry に保存
Weave と W&B Models の両方に評価結果をログ記録します。
# W&B の追跡を伴う評価の実行
with weave.attributes({"wandb-run-id": wandb.run.id}):
summary, call = await evaluation.evaluate.call(evaluation, model)
# W&B Models にメトリクスをログ記録
wandb.run.log(summary)
wandb.run.config.update({
"weave_eval_url": f"https://wandb.ai/{entity}/{project}/r/call/{call.id}"
})
高度な Weave 機能
カスタム scorer と judge
ユースケースに合わせて洗練された評価メトリクスを作成します。
@weave.op()
def llm_judge_scorer(expected: str, output: str, judge_model) -> dict:
prompt = f"この回答は正しいですか? 期待値: {expected}, 出力: {output}"
judgment = await judge_model.predict(prompt)
return {"judge_score": judgment}
バッチ評価
複数のモデルバージョンや設定を評価します。
models = [
ChatModel(model_name="model:v1"),
ChatModel(model_name="model:v2"),
]
for model in models:
results = await evaluation.evaluate(model)
print(f"{model.model_name}: {results}")
次のステップ
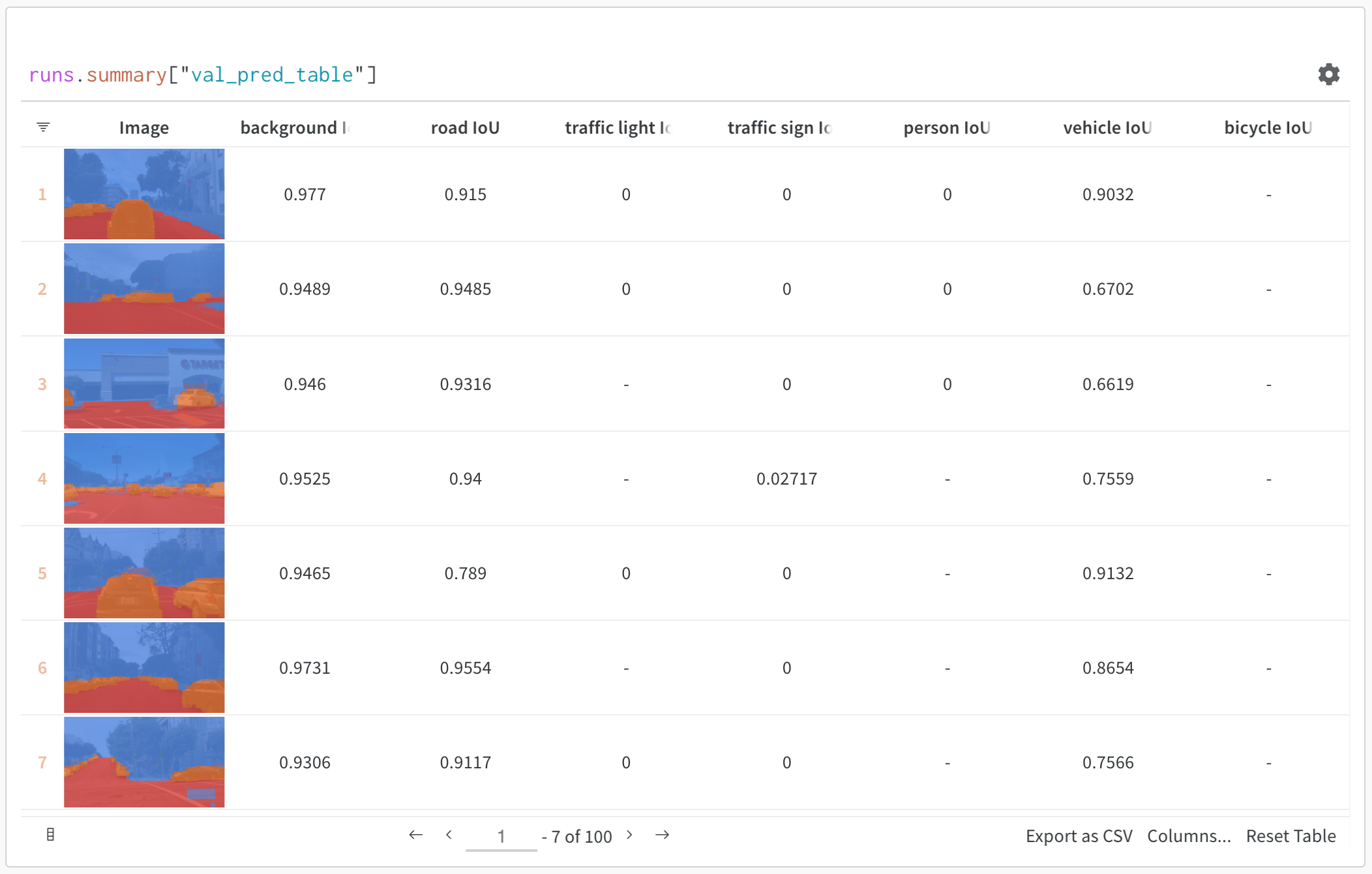
Tables を使用したモデルの評価
W&B Tables を使用して以下を行います:
- モデル予測の比較: 同じテストセットに対して異なるモデルがどのように機能するかを並べて比較
- 予測の変化を追跡: トレーニングのエポックやモデルのバージョン間で予測がどのように進化するかを監視
- エラーの分析: フィルタリングとクエリを使用して、よくある誤分類の例やエラーパターンを特定
- リッチメディアの可視化: 予測やメトリクスとともに、画像、音声、テキスト、その他のメディアタイプを表示
基本的な例:評価結果をログ記録する
import wandb
# run を初期化
run = wandb.init(project="model-evaluation")
# 評価結果を含むテーブルを作成
columns = ["id", "input", "ground_truth", "prediction", "confidence", "correct"]
eval_table = wandb.Table(columns=columns)
# 評価データを追加
for idx, (input_data, label) in enumerate(test_dataset):
prediction = model(input_data)
confidence = prediction.max()
predicted_class = prediction.argmax()
eval_table.add_data(
idx,
wandb.Image(input_data), # 画像やその他のメディアをログ記録
label,
predicted_class,
confidence,
label == predicted_class
)
# テーブルをログ記録
run.log({"evaluation_results": eval_table})
高度なテーブルワークフロー
複数のモデルを比較する
直接比較するために、異なるモデルからの評価テーブルを同じキーでログ記録します。
# モデル A の評価
with wandb.init(project="model-comparison", name="model_a") as run:
eval_table_a = create_eval_table(model_a, test_data)
run.log({"test_predictions": eval_table_a})
# モデル B の評価
with wandb.init(project="model-comparison", name="model_b") as run:
eval_table_b = create_eval_table(model_b, test_data)
run.log({"test_predictions": eval_table_b})
時間経過に伴う予測の追跡
改善を可視化するために、異なるトレーニングエポックでテーブルをログ記録します。
for epoch in range(num_epochs):
train_model(model, train_data)
# このエポックの予測を評価してログ記録
eval_table = wandb.Table(columns=["image", "truth", "prediction"])
for image, label in test_subset:
pred = model(image)
eval_table.add_data(wandb.Image(image), label, pred.argmax())
wandb.log({f"predictions_epoch_{epoch}": eval_table})
W&B UI でのインタラクティブな分析
ログ記録が完了すると、以下が可能になります:
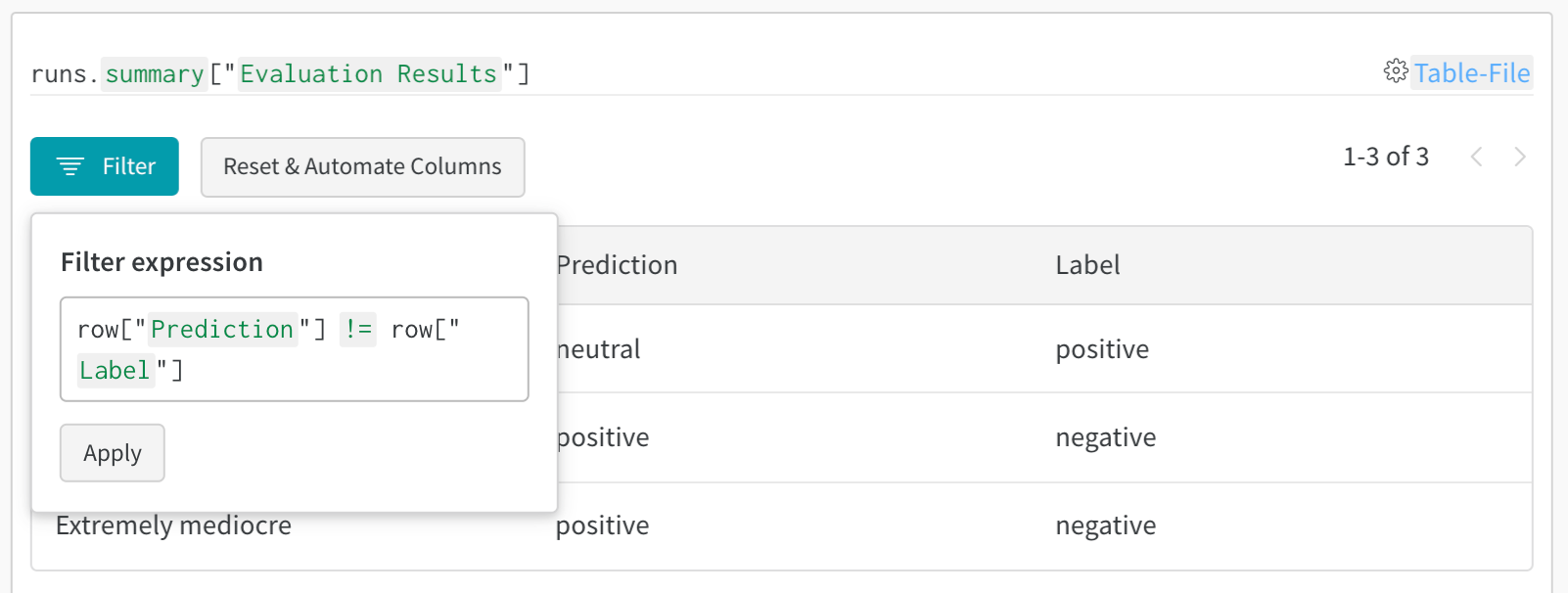
- 結果のフィルタリング: 列ヘッダーをクリックして、予測精度、確信度のしきい値、または特定のクラスでフィルタリング
- テーブルの比較: 複数のテーブルバージョンを選択して、並べて比較を表示
- データのクエリ: クエリバーを使用して特定のパターンを検索(例:
"correct" = false AND "confidence" > 0.8)
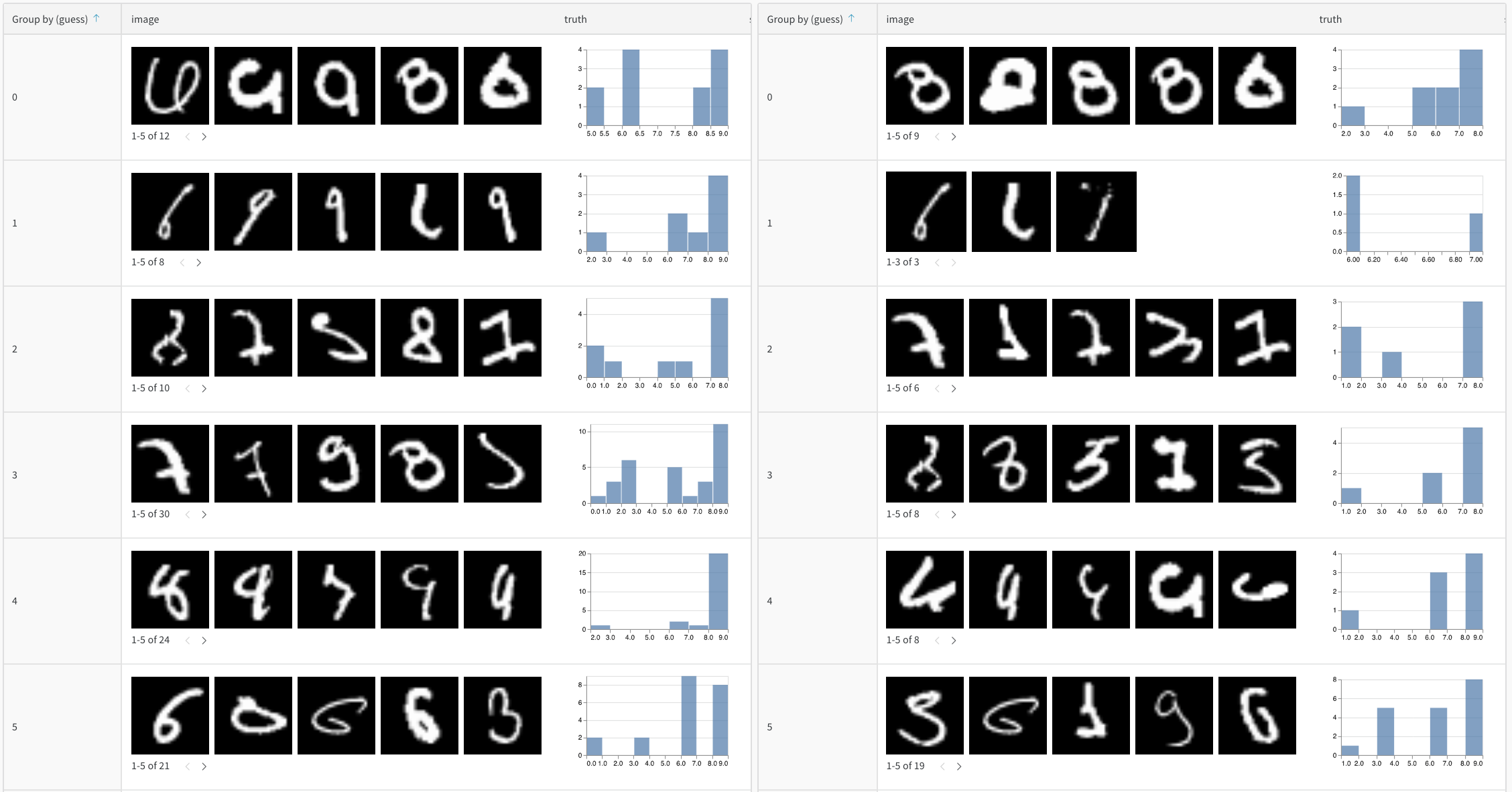
- グループ化と集計: 予測されたクラスでグループ化し、クラスごとの精度メトリクスを確認
例:拡張されたテーブルによるエラー分析
# 分析用の列を追加するためにミュータブルなテーブルを作成
eval_table = wandb.Table(
columns=["id", "image", "label", "prediction"],
log_mode="MUTABLE" # 後で列を追加可能にする
)
# 初期の予測
for idx, (img, label) in enumerate(test_data):
pred = model(img)
eval_table.add_data(idx, wandb.Image(img), label, pred.argmax())
run.log({"eval_analysis": eval_table})
# エラー分析のために確信度スコアを追加
confidences = [model(img).max() for img, _ in test_data]
eval_table.add_column("confidence", confidences)
# エラータイプを追加
error_types = classify_errors(eval_table.get_column("label"),
eval_table.get_column("prediction"))
eval_table.add_column("error_type", error_types)
run.log({"eval_analysis": eval_table})