Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-weave-caching.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
W&B Pythonライブラリを使用してCSVファイルをログに記録し、 W&B Dashboard で可視化します。 W&B Dashboard は、機械学習モデルの結果を整理して可視化するための中心的な場所です。これは、W&Bにログが記録されていない 過去の機械学習実験の情報を含むCSVファイル がある場合や、 データセットを含むCSVファイル がある場合に特に便利です。
データセットのCSVファイルをインポートしてログに記録する
CSVファイルの内容をより簡単に再利用できるようにするために、 W&B Artifacts を活用することをお勧めします。
- まず、CSVファイルをインポートします。以下のコードスニペットで、
iris.csv をお手元のCSVファイル名に置き換えてください。
import wandb
import pandas as pd
# CSVを新しいDataFrameに読み込む
new_iris_dataframe = pd.read_csv("iris.csv")
- CSVファイルを W&B Table に変換して、 W&B Dashboards を利用できるようにします。
# DataFrameをW&B Tableに変換する
iris_table = wandb.Table(dataframe=new_iris_dataframe)
- 次に、 W&B Artifact を作成し、その Artifact にテーブルを追加します。
# テーブルをArtifactに追加して、行制限を200,000に増やし、
# 再利用しやすくする
iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# データを保存するために、生のcsvファイルをアーティファクト内にログ記録する
iris_table_artifact.add_file("iris.csv")
- 最後に、
wandb.init を使用して新しい W&B Run を開始し、W&Bへのトラッキングとログ記録を行います。
# データをログに記録するためのW&B runを開始する
with wandb.init(project="tables-walkthrough") as run:
# runで可視化するためにテーブルをログに記録する...
run.log({"iris": iris_table})
# さらにArtifactとしてログに記録し、利用可能な行制限を増やす!
run.log_artifact(iris_table_artifact)
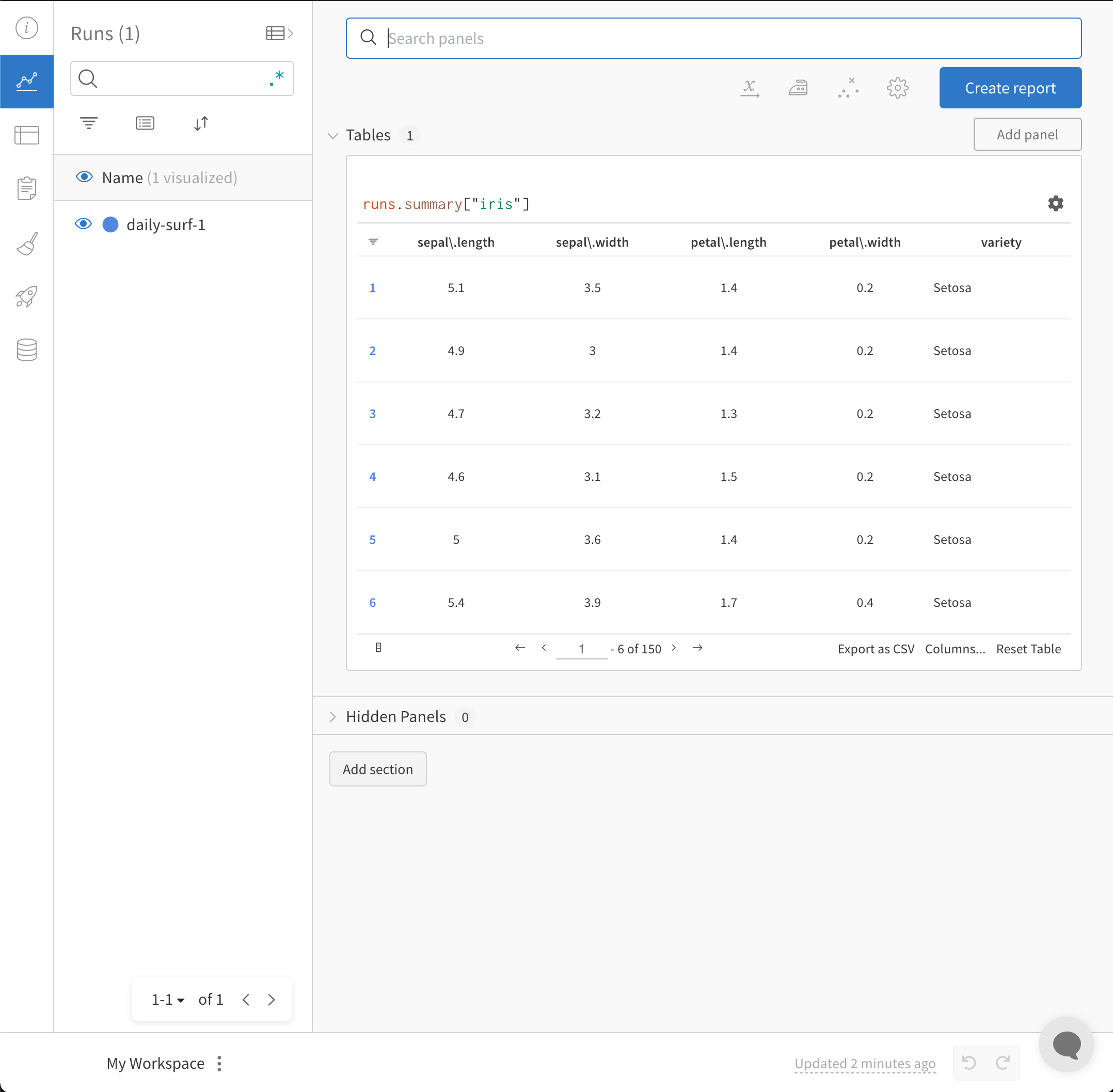
wandb.init() APIは、 Run にデータをログ記録するための新しいバックグラウンドプロセスを生成し、(デフォルトで)データを wandb.ai に同期します。 W&B Workspace Dashboard でライブの可視化を確認できます。以下の画像は、コードスニペットのデモンストレーションの出力を示しています。
上記のコードスニペットをまとめた完全なスクリプトは以下の通りです。
import wandb
import pandas as pd
# CSVを新しいDataFrameに読み込む
new_iris_dataframe = pd.read_csv("iris.csv")
# DataFrameをW&B Tableに変換する
iris_table = wandb.Table(dataframe=new_iris_dataframe)
# テーブルをArtifactに追加して、行制限を200,000に増やし、
# 再利用しやすくする
iris_table_artifact = wandb.Artifact("iris_artifact", type="dataset")
iris_table_artifact.add(iris_table, "iris_table")
# データを保存するために、生のcsvファイルをアーティファクト内にログ記録する
iris_table_artifact.add_file("iris.csv")
# データをログに記録するためのW&B runを開始する
with wandb.init(project="tables-walkthrough") as run:
# runで可視化するためにテーブルをログに記録する...
run.log({"iris": iris_table})
# さらにArtifactとしてログに記録し、利用可能な行制限を増やす!
run.log_artifact(iris_table_artifact)
実験のCSVをインポートしてログに記録する
場合によっては、実験の詳細がCSVファイルに保存されていることがあります。このようなCSVファイルで見られる一般的な詳細には以下のものがあります。
| Experiment | Model Name | Notes | Tags | Num Layers | Final Train Acc | Final Val Acc | Training Losses |
|---|
| Experiment 1 | mnist-300-layers | Overfit way too much on training data | [latest] | 300 | 0.99 | 0.90 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Experiment 2 | mnist-250-layers | Current best model | [prod, best] | 250 | 0.95 | 0.96 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| Experiment 3 | mnist-200-layers | Did worse than the baseline model. Need to debug | [debug] | 200 | 0.76 | 0.70 | [0.55, 0.45, 0.44, 0.42, 0.40, 0.39] |
| … | … | … | … | … | … | … | |
| Experiment N | mnist-X-layers | NOTES | … | … | … | … | […, …] |
- まず、CSVファイルを読み込み、Pandas DataFrameに変換します。
"experiments.csv" をお手元のCSVファイル名に置き換えてください。
import wandb
import pandas as pd
FILENAME = "experiments.csv"
loaded_experiment_df = pd.read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers"]
SUMMARY_COLS = ["Final Train Acc", "Final Val Acc"]
METRIC_COLS = ["Training Losses"]
# 操作しやすいようにPandas DataFrameをフォーマットする
for i, row in loaded_experiment_df.iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
-
次に、
wandb.init() を使用して新しい W&B Run を開始し、W&Bへのトラッキングとログ記録を行います。
with wandb.init(
project=PROJECT_NAME, name=run_name, tags=tags, notes=notes, config=config
) as run:
実験が進むにつれて、メトリクスのすべてのインスタンスをログに記録し、W&Bで表示、クエリ、分析できるようにしたい場合があります。これを行うには run.log() コマンドを使用します。
オプションで、 define_metric APIを使用して、 Run の結果を定義する最終的なサマリーメトリクスをログに記録できます。この例では、 run.summary.update() を使用してサマリーメトリクスを Run に追加しています。
run.summary.update(summaries)
FILENAME = "experiments.csv"
loaded_experiment_df = pd.read_csv(FILENAME)
PROJECT_NAME = "Converted Experiments"
EXPERIMENT_NAME_COL = "Experiment"
NOTES_COL = "Notes"
TAGS_COL = "Tags"
CONFIG_COLS = ["Num Layers"]
SUMMARY_COLS = ["Final Train Acc", "Final Val Acc"]
METRIC_COLS = ["Training Losses"]
for i, row in loaded_experiment_df.iterrows():
run_name = row[EXPERIMENT_NAME_COL]
notes = row[NOTES_COL]
tags = row[TAGS_COL]
config = {}
for config_col in CONFIG_COLS:
config[config_col] = row[config_col]
metrics = {}
for metric_col in METRIC_COLS:
metrics[metric_col] = row[metric_col]
summaries = {}
for summary_col in SUMMARY_COLS:
summaries[summary_col] = row[summary_col]
with wandb.init(
project=PROJECT_NAME, name=run_name, tags=tags, notes=notes, config=config
) as run:
for key, val in metrics.items():
if isinstance(val, list):
for _val in val:
run.log({key: _val})
else:
run.log({key: val})
run.summary.update(summaries)