Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-weave-caching.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用してください: Chain of Density を用いた要約
重要な詳細を維持しながら複雑な技術文書を要約することは、困難な課題です。Chain of Density(CoD)要約手法は、要約を繰り返し洗練させ、より簡潔で情報密度の高いものにすることで、この課題への解決策を提示します。このガイドでは、アプリケーションの追跡と評価に Weave を使用して CoD を実装する方法をデモします。
Chain of Density 要約とは?
 Chain of Density(CoD)は、段階的に簡潔で情報密度の高い要約を作成する反復的な要約手法です。以下の手順で動作します。
Chain of Density(CoD)は、段階的に簡潔で情報密度の高い要約を作成する反復的な要約手法です。以下の手順で動作します。
- 最初の要約から開始する
- 要約を繰り返し洗練させ、主要な情報を保持しながらより簡潔にする
- 反復ごとにエンティティ(固有表現)や技術的な詳細の密度を高める
このアプローチは、詳細な情報の保持が極めて重要な科学論文や技術文書の要約に特に有用です。
なぜ Weave を使うのか?
このチュートリアルでは、Weave を使用して ArXiv 論文向けの Chain of Density 要約パイプラインを実装し、評価します。以下の方法を学習します。
- LLM パイプラインの追跡: Weave を使用して、要約プロセスの入力、出力、および中間ステップを自動的にログに記録します。
- LLM 出力の評価: Weave の組み込みツールを使用して、要約の厳密で公平な(apples-to-apples)評価を作成します。
- 構成可能な操作の構築: 要約パイプラインの異なる部分で Weave の operation を組み合わせ、再利用します。
- シームレスな統合: 最小限のオーバーヘッドで、既存の Python コードに Weave を追加します。
このチュートリアルの最後には、モデルのサービング、評価、および結果の追跡に Weave の機能を活用した CoD 要約パイプラインが完成します。
環境のセットアップ
まず、環境をセットアップし、必要なライブラリをインポートしましょう。
!pip install -qU anthropic weave pydantic requests PyPDF2 set-env-colab-kaggle-dotenv
Anthropic の APIキー を取得するには:
- https://www.anthropic.com でアカウントを登録します
- アカウント設定の API セクションに移動します
- 新しい APIキー を生成します
- .env ファイルに APIキー を安全に保存します
import io
import os
from datetime import datetime, timezone
import anthropic
import requests
from pydantic import BaseModel
from PyPDF2 import PdfReader
from set_env import set_env
import weave
set_env("WANDB_API_KEY")
set_env("ANTHROPIC_API_KEY")
# Weave プロジェクトを初期化
weave.init("summarization-chain-of-density-cookbook")
anthropic_client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
weave.init(<project name>) を呼び出すことで、要約タスク用の新しい Weave プロジェクトがセットアップされます。
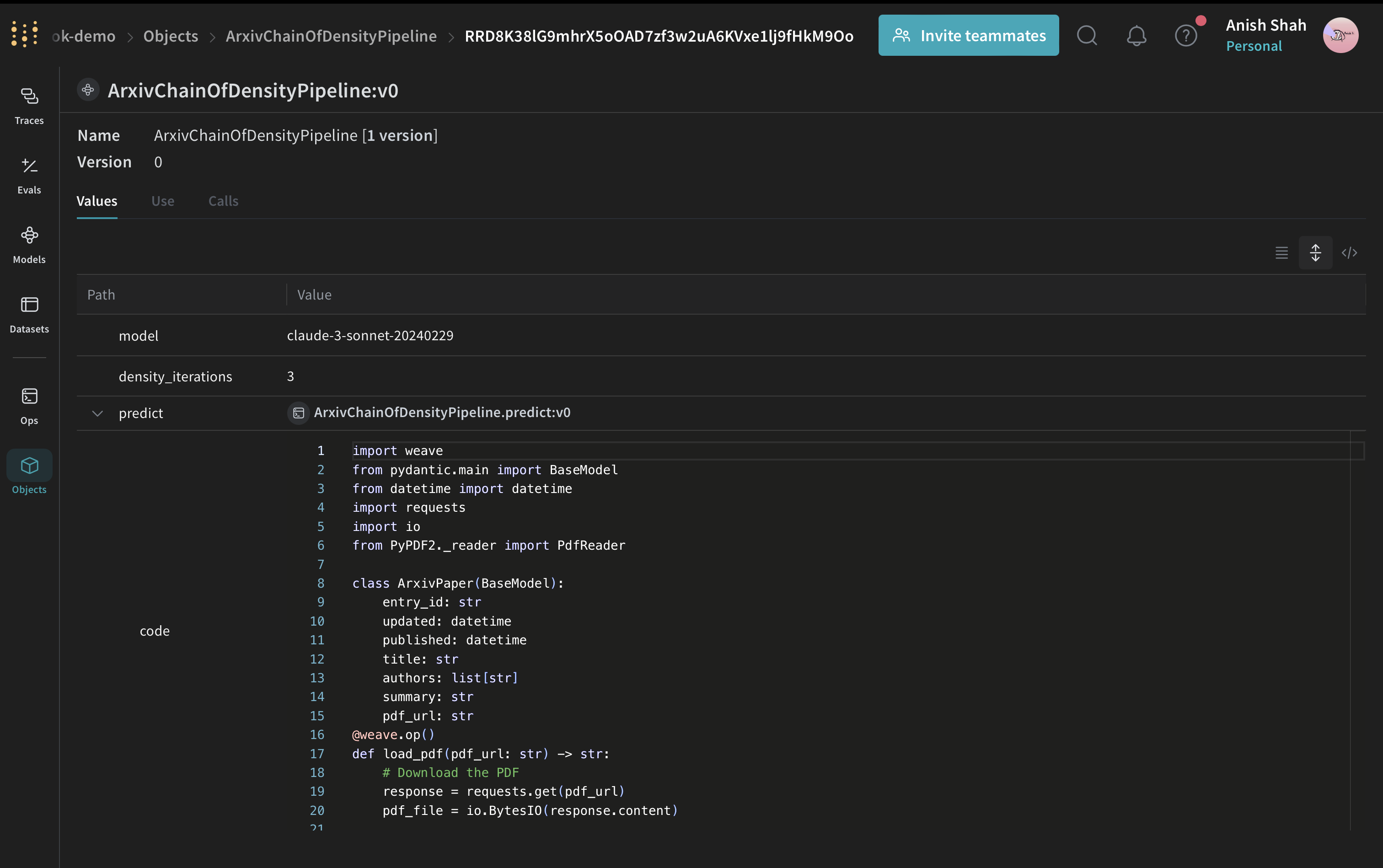
ArxivPaper モデルの定義
データを表すためのシンプルな ArxivPaper クラスを作成します。
# ArxivPaper モデルの定義
class ArxivPaper(BaseModel):
entry_id: str
updated: datetime
published: datetime
title: str
authors: list[str]
summary: str
pdf_url: str
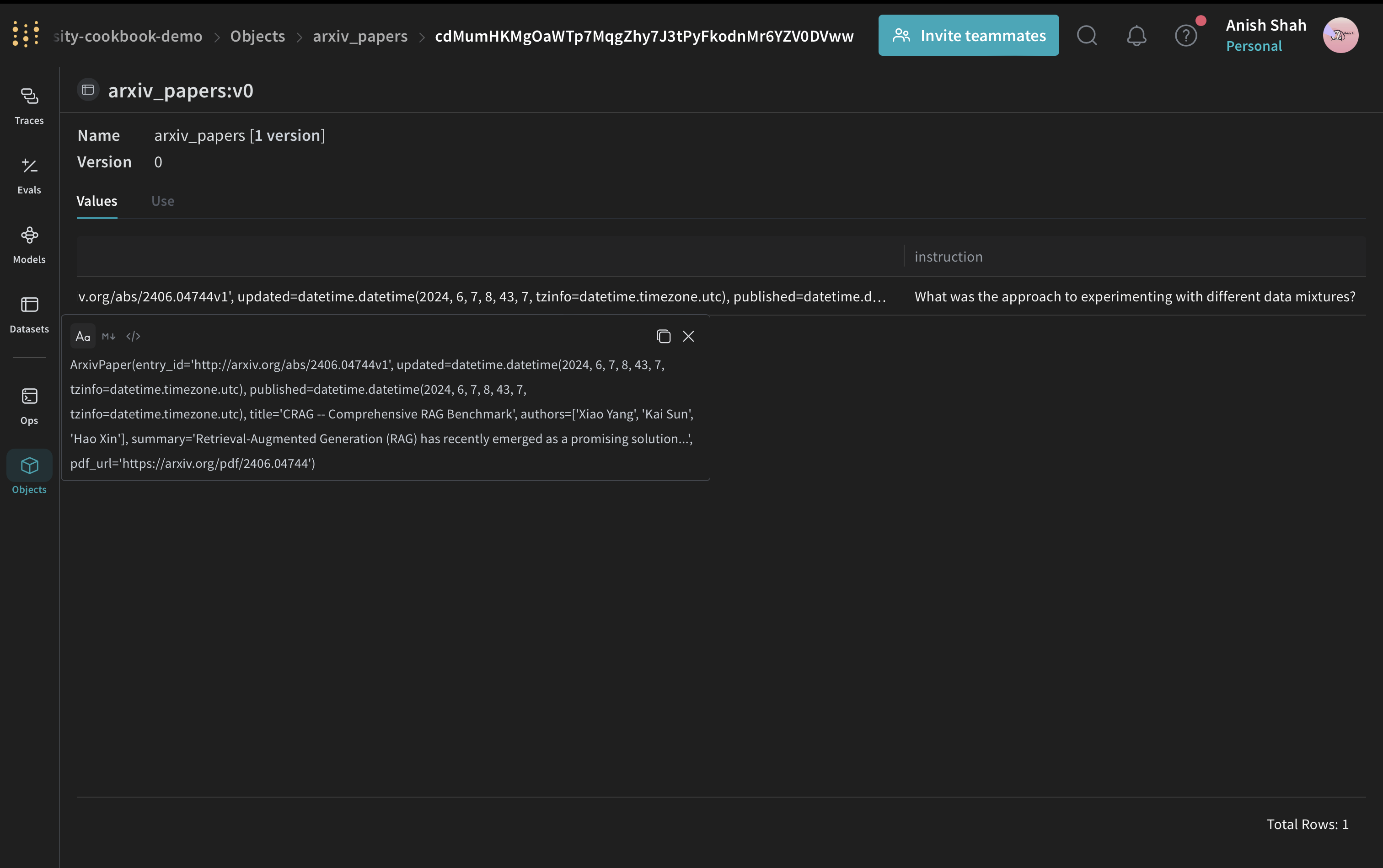
# サンプルの ArxivPaper を作成
arxiv_paper = ArxivPaper(
entry_id="http://arxiv.org/abs/2406.04744v1",
updated=datetime(2024, 6, 7, 8, 43, 7, tzinfo=timezone.utc),
published=datetime(2024, 6, 7, 8, 43, 7, tzinfo=timezone.utc),
title="CRAG -- Comprehensive RAG Benchmark",
authors=["Xiao Yang", "Kai Sun", "Hao Xin"], # 簡略化のため省略
summary="Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution...", # 省略
pdf_url="https://arxiv.org/pdf/2406.04744",
)
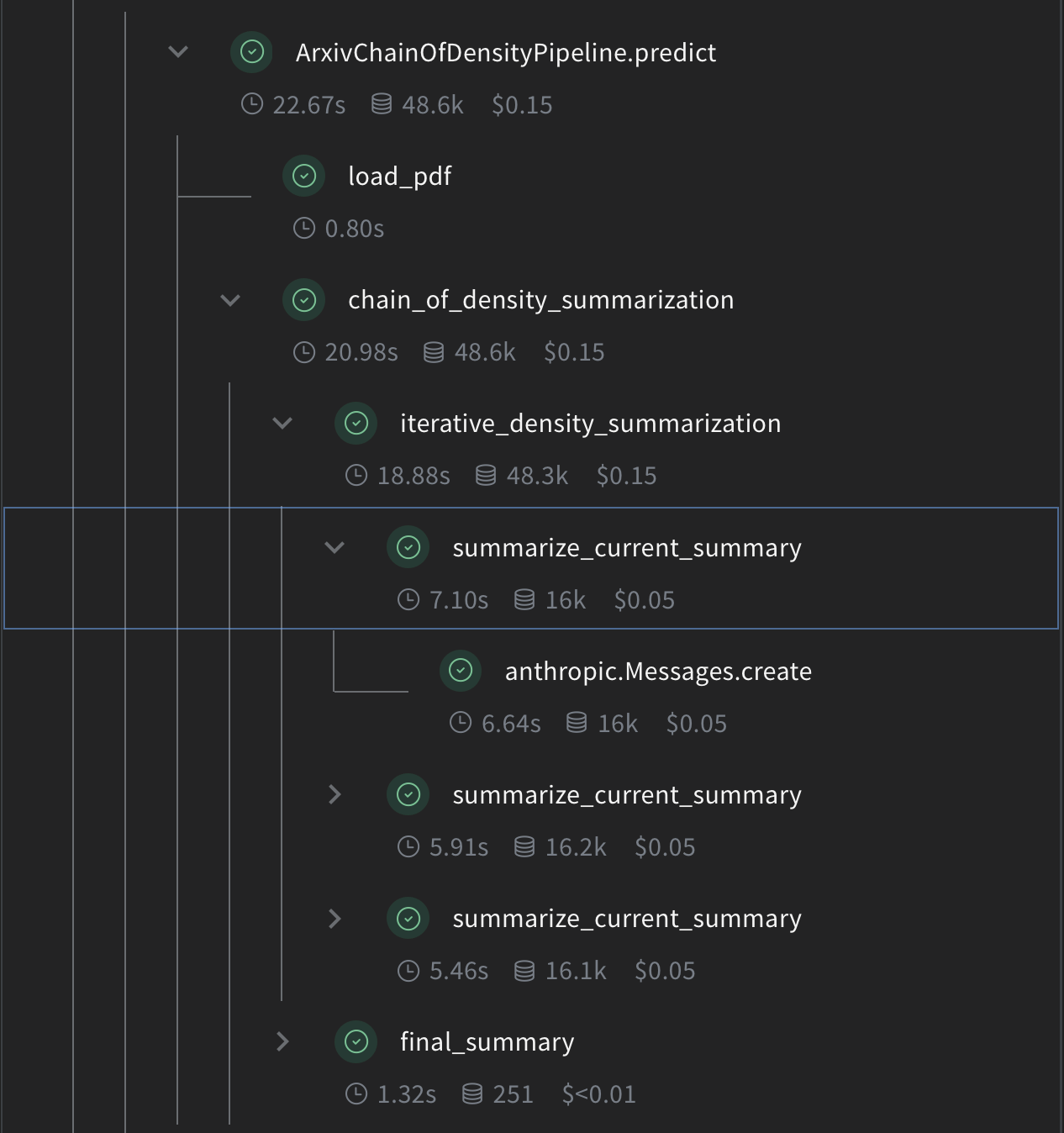
PDF コンテンツのロード
論文の全文を扱うために、PDF をロードしてテキストを抽出する関数を追加します。
@weave.op()
def load_pdf(pdf_url: str) -> str:
# PDF をダウンロード
response = requests.get(pdf_url)
pdf_file = io.BytesIO(response.content)
# PDF を読み込み
pdf_reader = PdfReader(pdf_file)
# 全ページからテキストを抽出
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
return text
Chain of Density 要約の実装
次に、Weave の operation を使用して CoD 要約のコアロジックを実装します。
# Chain of Density 要約
@weave.op()
def summarize_current_summary(
document: str,
instruction: str,
current_summary: str = "",
iteration: int = 1,
model: str = "claude-3-sonnet-20240229",
):
prompt = f"""
Document: {document}
Current summary: {current_summary}
Instruction to focus on: {instruction}
Iteration: {iteration}
Generate an increasingly concise, entity-dense, and highly technical summary from the provided document that specifically addresses the given instruction.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
@weave.op()
def iterative_density_summarization(
document: str,
instruction: str,
current_summary: str,
density_iterations: int,
model: str = "claude-3-sonnet-20240229",
):
iteration_summaries = []
for iteration in range(1, density_iterations + 1):
current_summary = summarize_current_summary(
document, instruction, current_summary, iteration, model
)
iteration_summaries.append(current_summary)
return current_summary, iteration_summaries
@weave.op()
def final_summary(
instruction: str, current_summary: str, model: str = "claude-3-sonnet-20240229"
):
prompt = f"""
Given this summary: {current_summary}
And this instruction to focus on: {instruction}
Create an extremely dense, final summary that captures all key technical information in the most concise form possible, while specifically addressing the given instruction.
"""
return (
anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
.content[0]
.text
)
@weave.op()
def chain_of_density_summarization(
document: str,
instruction: str,
current_summary: str = "",
model: str = "claude-3-sonnet-20240229",
density_iterations: int = 2,
):
current_summary, iteration_summaries = iterative_density_summarization(
document, instruction, current_summary, density_iterations, model
)
final_summary_text = final_summary(instruction, current_summary, model)
return {
"final_summary": final_summary_text,
"accumulated_summary": current_summary,
"iteration_summaries": iteration_summaries,
}
summarize_current_summary: 現在の状態に基づき、1回の要約反復を生成します。iterative_density_summarization: summarize_current_summary を複数回呼び出すことで CoD 手法を適用します。chain_of_density_summarization: 要約プロセス全体をオーケストレートし、結果を返します。
@weave.op() デコレータを使用することで、Weave がこれらの関数の入力、出力、および実行を確実に追跡できるようになります。
Weave Model の作成
次に、要約パイプラインを Weave Model でラップしましょう。
# Weave Model
class ArxivChainOfDensityPipeline(weave.Model):
model: str = "claude-3-sonnet-20240229"
density_iterations: int = 3
@weave.op()
def predict(self, paper: ArxivPaper, instruction: str) -> dict:
text = load_pdf(paper.pdf_url)
result = chain_of_density_summarization(
text,
instruction,
model=self.model,
density_iterations=self.density_iterations,
)
return result
ArxivChainOfDensityPipeline クラスは要約ロジックを Weave Model としてカプセル化し、いくつかの主要なメリットを提供します。
- 自動的な実験管理: Weave はモデルの各実行における入力、出力、およびパラメータをキャプチャします。
- バージョン管理: モデルの属性やコードへの変更は自動的にバージョン管理され、要約パイプラインの進化の歴史を明確にします。
- 再現性: バージョン管理と追跡により、要約パイプラインの以前の結果や設定を簡単に再現できます。
- ハイパーパラメーター管理: モデル属性(
model や density_iterations など)が明確に定義および追跡され、実験を促進します。
- Weave エコシステムとの統合:
weave.Model を使用することで、評価やサービング機能など、他の Weave ツールとシームレスに統合できます。
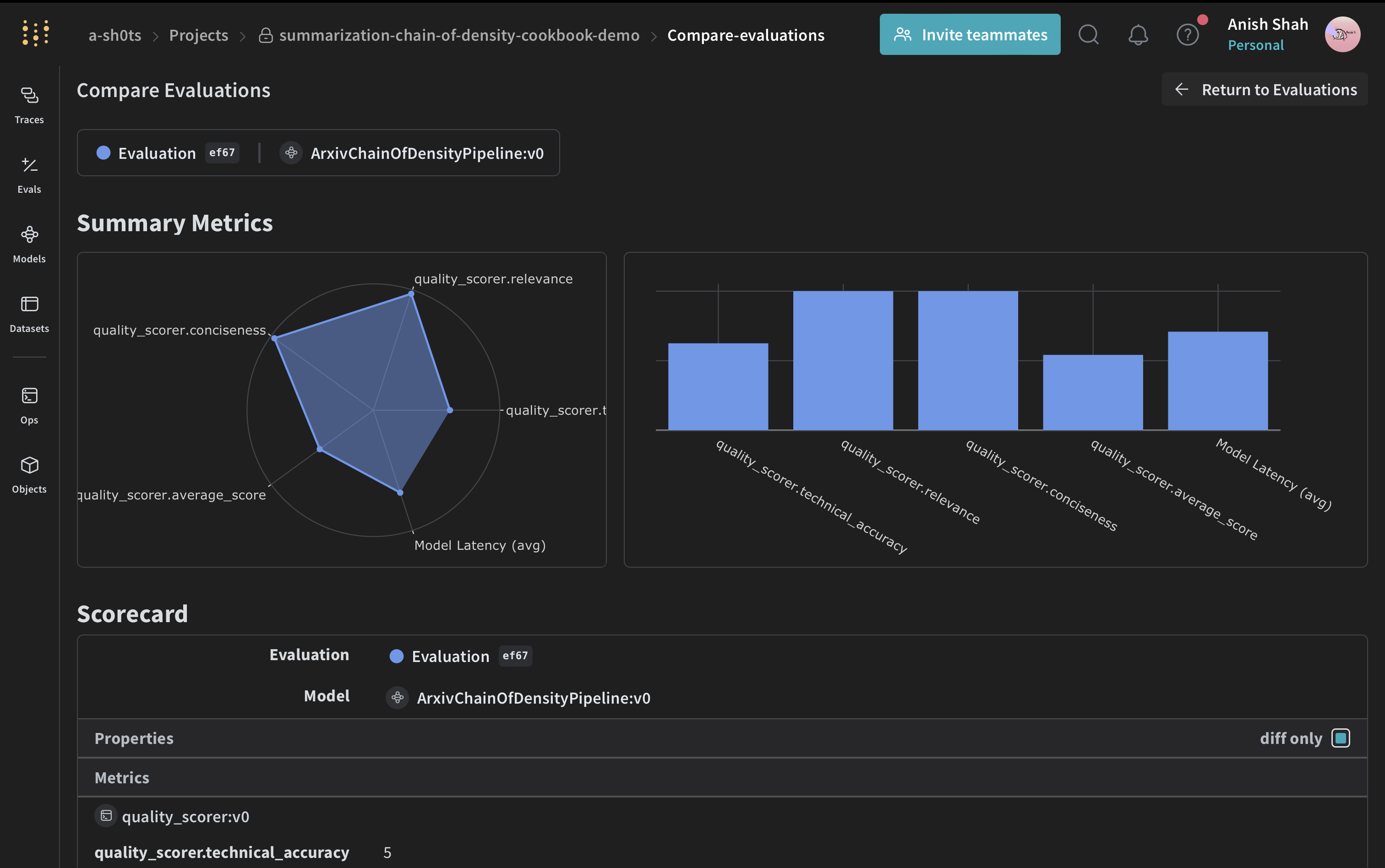
評価メトリクスの実装
要約の質を評価するために、シンプルな評価メトリクスを実装します。
import json
@weave.op()
def evaluate_summary(
summary: str, instruction: str, model: str = "claude-3-sonnet-20240229"
) -> dict:
prompt = f"""
Summary: {summary}
Instruction: {instruction}
Evaluate the summary based on the following criteria:
1. Relevance (1-5): How well does the summary address the given instruction?
2. Conciseness (1-5): How concise is the summary while retaining key information?
3. Technical Accuracy (1-5): How accurately does the summary convey technical details?
Your response MUST be in the following JSON format:
{{
"relevance": {{
"score": <int>,
"explanation": "<string>"
}},
"conciseness": {{
"score": <int>,
"explanation": "<string>"
}},
"technical_accuracy": {{
"score": <int>,
"explanation": "<string>"
}}
}}
Ensure that the scores are integers between 1 and 5, and that the explanations are concise.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=1000, messages=[{"role": "user", "content": prompt}]
)
print(response.content[0].text)
eval_dict = json.loads(response.content[0].text)
return {
"relevance": eval_dict["relevance"]["score"],
"conciseness": eval_dict["conciseness"]["score"],
"technical_accuracy": eval_dict["technical_accuracy"]["score"],
"average_score": sum(eval_dict[k]["score"] for k in eval_dict) / 3,
"evaluation_text": response.content[0].text,
}
Weave Dataset の作成と評価の実行
パイプラインを評価するために、Weave Dataset を作成して評価を実行します。
# Weave Dataset を作成
dataset = weave.Dataset(
name="arxiv_papers",
rows=[
{
"paper": arxiv_paper,
"instruction": "What was the approach to experimenting with different data mixtures?",
},
],
)
weave.publish(dataset)

# スカラー関数を定義
@weave.op()
def quality_scorer(instruction: str, output: dict) -> dict:
result = evaluate_summary(output["final_summary"], instruction)
return result
# 評価の実行
evaluation = weave.Evaluation(dataset=dataset, scorers=[quality_scorer])
arxiv_chain_of_density_pipeline = ArxivChainOfDensityPipeline()
results = await evaluation.evaluate(arxiv_chain_of_density_pipeline)
- 要約プロセスの各ステップに対して Weave operation を作成する方法
- 追跡と評価を容易にするためにパイプラインを Weave Model でラップする方法
- Weave operation を使用してカスタム評価メトリクスを実装する方法
- データセットを作成し、パイプラインの評価を実行する方法
Weave のシームレスな統合により、要約プロセス全体の入力、出力、中間ステップを追跡でき、LLM アプリケーションのデバッグ、最適化、評価が容易になります。
この例を拡張して、より大規模なデータセットを扱ったり、より洗練された評価メトリクスを実装したり、他の LLM ワークフローと統合したりすることができます。
W&B でフルレポートを表示