Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-weave-caching.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用してください: PII データで Weave を使用する方法
このガイドでは、個人識別情報(PII)データのプライバシーを確保しながら W&B Weave を使用する方法を学びます。このガイドでは、PII データを特定、墨消し(redact)、および匿名化するための以下の手法をデモします:
- 正規表現 を使用して PII データを特定し、墨消しする。
- Microsoft の Presidio:Python ベースのデータ保護 SDK。このツールは墨消しおよび置換機能を提供します。
- Faker:偽のデータを生成するための Python ライブラリ。Presidio と組み合わせて PII データを匿名化します。
さらに、weave.op の入力/出力ログのカスタマイズ と autopatch_settings を使用して、PII の墨消しと匿名化をワークフローに統合する方法についても学びます。詳細については、ログに記録される入力と出力のカスタマイズ を参照してください。
開始するには、以下を行ってください:
- 概要 セクションを確認する。
- 事前準備 を完了する。
- PII データの特定、墨消し、匿名化のための 利用可能な手法 を確認する。
- Weave の呼び出しにメソッドを適用する。
以下のセクションでは、weave.op を使用した入力と出力のログ記録の概要、および Weave で PII データを扱う際のベストプラクティスについて説明します。
weave.op を使用した入力と出力のログ記録のカスタマイズ
Weave Ops では、入力および出力の後処理関数を定義できます。これらの関数を使用することで、LLM 呼び出しに渡されるデータや Weave にログ記録されるデータを変更できます。
以下の例では、2 つの後処理関数が定義され、weave.op() の引数として渡されています。
from dataclasses import dataclass
from typing import Any
import weave
# 入力用ラッパークラス
@dataclass
class CustomObject:
x: int
secret_password: str
# まず、入力と出力の後処理用関数を定義します:
def postprocess_inputs(inputs: dict[str, Any]) -> dict[str, Any]:
return {k:v for k,v in inputs.items() if k != "hide_me"}
def postprocess_output(output: CustomObject) -> CustomObject:
return CustomObject(x=output.x, secret_password="REDACTED")
# 次に、@weave.op デコレータを使用する際に、これらの処理関数をデコレータの引数として渡します:
@weave.op(
postprocess_inputs=postprocess_inputs,
postprocess_output=postprocess_output,
)
def some_llm_call(a: int, hide_me: str) -> CustomObject:
return CustomObject(x=a, secret_password=hide_me)
PII データで Weave を使用するためのベストプラクティス
PII データで Weave を使用する前に、以下のベストプラクティスを確認してください。
テスト中
- 匿名化されたデータをログに記録し、PII 検出を確認する
- PII の取り扱いプロセスを Weave Traces で追跡する
- 実際の PII を公開せずに匿名化のパフォーマンスを測定する
プロダクション環境
- 生の PII を決してログに記録しない
- ログを記録する前に機密フィールドを暗号化する
暗号化のヒント
- 後で復号する必要があるデータには可逆暗号を使用する
- 元に戻す必要のない一意の ID には一方向ハッシュを適用する
- 暗号化したまま分析が必要なデータには、専用の暗号化を検討する
事前準備
- まず、必要なパッケージをインストールします。
%%capture
# @title 必要な Python パッケージ:
!pip install cryptography
!pip install presidio_analyzer
!pip install presidio_anonymizer
!python -m spacy download en_core_web_lg # Presidio は spacy NLP エンジンを使用します
!pip install Faker # Faker を使用して PII データを偽データに置き換えます
!pip install weave # Traces を活用するため
!pip install set-env-colab-kaggle-dotenv -q # 環境変数用
!pip install anthropic # sonnet を使用するため
!pip install cryptography # データを暗号化するため
-
以下のサイトで APIキー を作成します:
%%capture
# @title API キーを正しく設定します
# 使用方法については https://pypi.org/project/set-env-colab-kaggle-dotenv/ を参照してください。
from set_env import set_env
_ = set_env("ANTHROPIC_API_KEY")
_ = set_env("WANDB_API_KEY")
- Weave プロジェクトを初期化します。
import weave
# 新しい Weave プロジェクトを開始します
WEAVE_PROJECT = "pii_cookbook"
weave.init(WEAVE_PROJECT)
- 10 個のテキストブロックを含むデモ PII データセットをロードします。
import requests
url = "https://raw.githubusercontent.com/wandb/weave/master/docs/notebooks/10_pii_data.json"
response = requests.get(url)
pii_data = response.json()
print('PII データの最初のサンプル: "' + pii_data[0]["text"] + '"')
墨消しメソッドの概要
セットアップ が完了したら、次のことができます。
PII データを検出して保護するために、以下の方法を用いて PII データを特定して墨消しし、オプションで匿名化します。
- 正規表現 を使用して PII データを特定し、墨消しする。
- Microsoft Presidio:墨消しおよび置換機能を提供する Python ベースのデータ保護 SDK。
- Faker:偽データを生成するための Python ライブラリ。
メソッド 1: 正規表現を使用したフィルタリング
正規表現 (regex) は、PII データを特定して墨消しするための最もシンプルな方法です。正規表現を使用すると、電話番号、メールアドレス、社会保障番号などのさまざまな形式の機密情報に一致するパターンを定義できます。正規表現を使用することで、複雑な NLP 技術を必要とせずに、大量のテキストをスキャンして情報を置換または墨消しできます。
import re
# 正規表現を使用して PII データをクリーニングする関数を定義
def redact_with_regex(text):
# 電話番号のパターン
# \b : 単語の境界
# \d{3} : ちょうど3桁の数字
# [-.]? : オプションのハイフンまたはドット
# \d{3} : さらに3桁の数字
# [-.]? : オプションのハイフンまたはドット
# \d{4} : ちょうど4桁の数字
# \b : 単語の境界
text = re.sub(r"\b\d{3}[-.]?\d{3}[-.]?\d{4}\b", "<PHONE>", text)
# メールアドレスのパターン
# \b : 単語の境界
# [A-Za-z0-9._%+-]+ : メールのユーザー名に使用できる1文字以上の文字
# @ : 文字通りの @ 記号
# [A-Za-z0-9.-]+ : ドメイン名に使用できる1文字以上の文字
# \. : 文字通りのドット
# [A-Z|a-z]{2,} : 2文字以上の英字(TLD)
# \b : 単語の境界
text = re.sub(
r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b", "<EMAIL>", text
)
# SSN(社会保障番号)のパターン
# \b : 単語の境界
# \d{3} : ちょうど3桁の数字
# - : 文字通りのハイフン
# \d{2} : ちょうど2桁の数字
# - : 文字通りのハイフン
# \d{4} : ちょうど4桁の数字
# \b : 単語の境界
text = re.sub(r"\b\d{3}-\d{2}-\d{4}\b", "<SSN>", text)
# シンプルな名前のパターン(これは包括的ではありません)
# \b : 単語の境界
# [A-Z] : 1つの大文字
# [a-z]+ : 1文字以上の小文字
# \s : 1つの空白文字
# [A-Z] : 1つの大文字
# [a-z]+ : 1文字以上の小文字
# \b : 単語の境界
text = re.sub(r"\b[A-Z][a-z]+ [A-Z][a-z]+\b", "<NAME>", text)
return text
# 関数のテスト
test_text = "My name is John Doe, my email is john.doe@example.com, my phone is 123-456-7890, and my SSN is 123-45-6789."
cleaned_text = redact_with_regex(test_text)
print(f"Raw text:\n\t{test_text}")
print(f"Redacted text:\n\t{cleaned_text}")
メソッド 2: Microsoft Presidio を使用した墨消し
次のメソッドは、Microsoft Presidio を使用して PII データを完全に削除する方法です。Presidio は PII を墨消しし、PII タイプを表すプレースホルダーに置き換えます。例えば、Presidio は "My name is Alex" の Alex を <PERSON> に置き換えます。
Presidio には、一般的なエンティティ のサポートが組み込まれています。以下の例では、PHONE_NUMBER、PERSON、LOCATION、EMAIL_ADDRESS、または US_SSN であるすべてのエンティティを墨消しします。Presidio のプロセスは関数にカプセル化されています。
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
# 分析器(Analyzer)をセットアップ。NLPモジュール(デフォルトはspaCyモデル)や他のPII認識器をロードします。
analyzer = AnalyzerEngine()
# 匿名化器(Anonymizer)をセットアップ。分析結果を使用してテキストを匿名化します。
anonymizer = AnonymizerEngine()
# Presidio の墨消しプロセスを関数にカプセル化
def redact_with_presidio(text):
# テキストを分析して PII データを特定
results = analyzer.analyze(
text=text,
entities=["PHONE_NUMBER", "PERSON", "LOCATION", "EMAIL_ADDRESS", "US_SSN"],
language="en",
)
# 特定された PII データを匿名化
anonymized_text = anonymizer.anonymize(text=text, analyzer_results=results)
return anonymized_text.text
text = "My phone number is 212-555-5555 and my name is alex"
# 関数のテスト
anonymized_text = redact_with_presidio(text)
print(f"Raw text:\n\t{text}")
print(f"Redacted text:\n\t{anonymized_text}")
メソッド 3: Faker と Presidio を使用した置換による匿名化
テキストを墨消しする代わりに、MS Presidio を使用して名前や電話番号などの PII を Faker Python ライブラリで生成された偽データに交換することで匿名化できます。例えば、次のようなデータがあるとします:
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
Presidio と Faker を使用して処理されると、次のようになります:
"My name is Katherine Dixon and I like to fish. My phone number is 667.431.7379"
Presidio と Faker を効果的に組み合わせて使用するには、カスタムオペレーターへの参照を提供する必要があります。これらのオペレーターは、PII を偽データに交換する役割を担う Faker 関数を Presidio に指示します。
from faker import Faker
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
fake = Faker()
# Faker 関数を作成(値を受け取る必要があることに注意)
def fake_name(x):
return fake.name()
def fake_number(x):
return fake.phone_number()
# PERSON および PHONE_NUMBER エンティティ用のカスタムオペレーターを作成
operators = {
"PERSON": OperatorConfig("custom", {"lambda": fake_name}),
"PHONE_NUMBER": OperatorConfig("custom", {"lambda": fake_number}),
}
text_to_anonymize = (
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
)
# 分析器の出力
analyzer_results = analyzer.analyze(
text=text_to_anonymize, entities=["PHONE_NUMBER", "PERSON"], language="en"
)
anonymizer = AnonymizerEngine()
# 上記のオペレーターを匿名化器に渡すのを忘れないでください
anonymized_results = anonymizer.anonymize(
text=text_to_anonymize, analyzer_results=analyzer_results, operators=operators
)
print(f"Raw text:\n\t{text_to_anonymize}")
print(f"Anonymized text:\n\t{anonymized_results.text}")
from typing import ClassVar
from faker import Faker
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
# Faker を拡張した偽データ生成用のカスタムクラス
class MyFaker(Faker):
# Faker 関数を作成(値を受け取る必要があることに注意)
def fake_address(self):
return fake.address()
def fake_ssn(self):
return fake.ssn()
def fake_name(self):
return fake.name()
def fake_number(self):
return fake.phone_number()
def fake_email(self):
return fake.email()
# エンティティ用のカスタムオペレーターを作成
operators: ClassVar[dict[str, OperatorConfig]] = {
"PERSON": OperatorConfig("custom", {"lambda": fake_name}),
"PHONE_NUMBER": OperatorConfig("custom", {"lambda": fake_number}),
"EMAIL_ADDRESS": OperatorConfig("custom", {"lambda": fake_email}),
"LOCATION": OperatorConfig("custom", {"lambda": fake_address}),
"US_SSN": OperatorConfig("custom", {"lambda": fake_ssn}),
}
def redact_and_anonymize_with_faker(self, text):
anonymizer = AnonymizerEngine()
analyzer_results = analyzer.analyze(
text=text,
entities=["PHONE_NUMBER", "PERSON", "LOCATION", "EMAIL_ADDRESS", "US_SSN"],
language="en",
)
anonymized_results = anonymizer.anonymize(
text=text, analyzer_results=analyzer_results, operators=self.operators
)
return anonymized_results.text
faker = MyFaker()
text_to_anonymize = (
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
)
anonymized_text = faker.redact_and_anonymize_with_faker(text_to_anonymize)
print(f"Raw text:\n\t{text_to_anonymize}")
print(f"Anonymized text:\n\t{anonymized_text}")
メソッド 4: autopatch_settings の使用
autopatch_settings を使用すると、サポートされている 1 つ以上の LLM インテグレーションに対して、初期化中に PII の処理を直接設定できます。この方法の利点は次のとおりです:
- PII 処理ロジックが初期化時に一元化およびスコープ定義されるため、カスタムロジックを散在させる必要がなくなります。
- 特定のインテグレーションに対して、PII 処理ワークフローをカスタマイズしたり、完全に無効にしたりできます。
autopatch_settings を使用して PII 処理を設定するには、サポートされている LLM インテグレーションのいずれかの op_settings 内で postprocess_inputs や postprocess_output を定義します。
def postprocess(inputs: dict) -> dict:
if "SENSITIVE_KEY" in inputs:
inputs["SENSITIVE_KEY"] = "REDACTED"
return inputs
client = weave.init(
...,
autopatch_settings={
"openai": {
"op_settings": {
"postprocess_inputs": postprocess,
"postprocess_output": ...,
}
},
"anthropic": {
"op_settings": {
"postprocess_inputs": ...,
"postprocess_output": ...,
}
}
},
)
Weave の呼び出しにメソッドを適用する
以下の例では、PII の墨消しおよび匿名化メソッドを Weave Models に統合し、Weave Traces で結果を確認します。
まず、Weave Model を作成します。Weave Model は、設定、モデルの重み、およびモデルの動作を定義するコードなどの情報の組み合わせです。
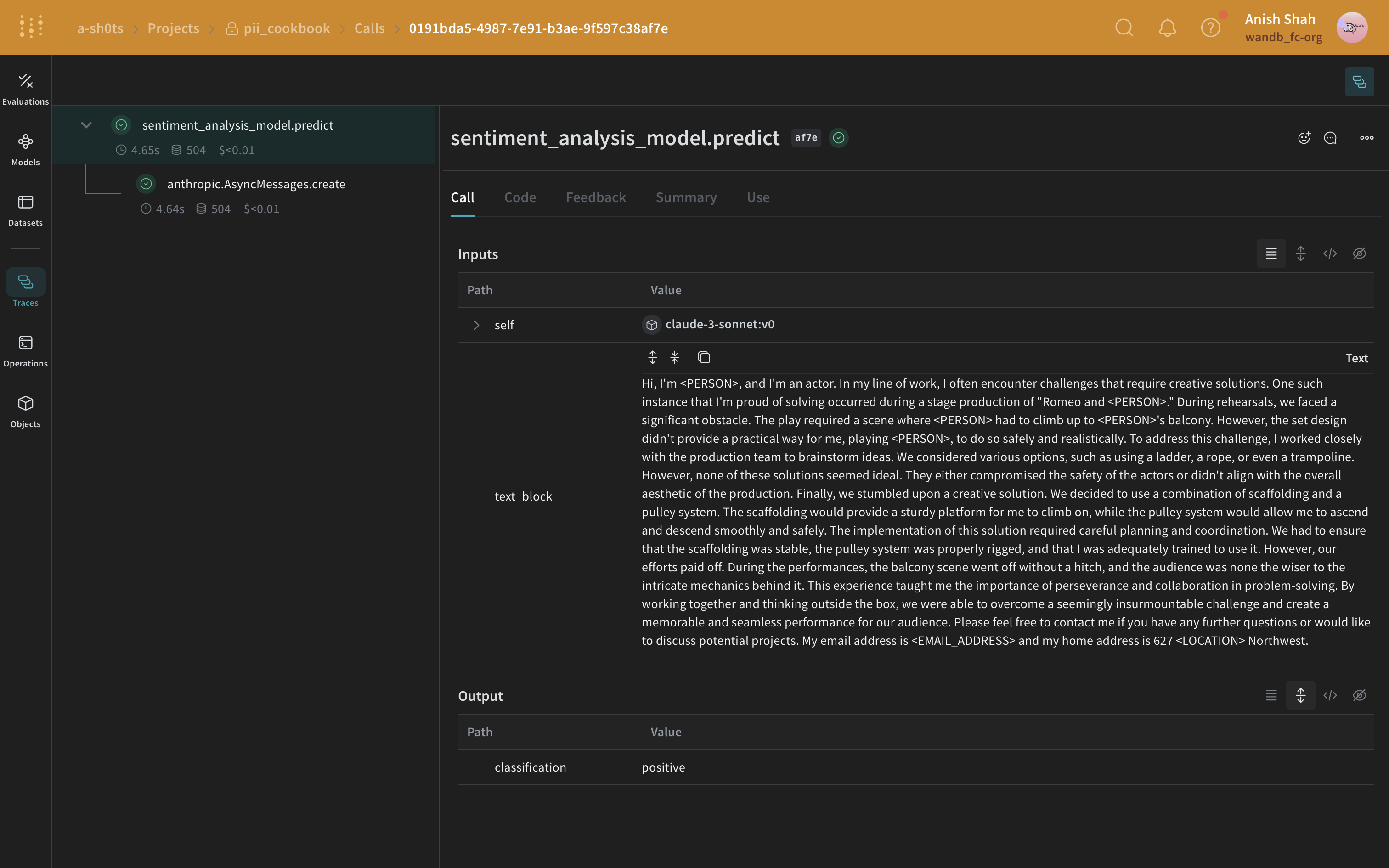
モデルには、Anthropic API が呼び出される predict 関数を含めます。Anthropic の Claude Sonnet を使用して Traces を行いながらセンチメント分析を実行します。Claude Sonnet はテキストブロックを受け取り、positive、negative、または neutral のいずれかのセンチメント分類を出力します。さらに、LLM に送信される前に PII データを墨消しまたは匿名化するための後処理関数を含めます。
このコードを実行すると、Weave プロジェクトページへのリンクと、実行した特定のトレース(LLM 呼び出し)へのリンクが表示されます。
正規表現メソッド
最もシンプルなケースとして、正規表現を使用して元のテキストから PII データを特定して墨消しできます。
import json
from typing import Any
import anthropic
import weave
# モデルの予測用 Weave Op に対して、正規表現による墨消しを適用する入力後処理関数を定義します
def postprocess_inputs_regex(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_regex(inputs["text_block"])
return inputs
# Weave モデル / 予測関数
class SentimentAnalysisRegexPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_regex,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
# システムプロンプトを含む LLM モデルを作成します
model = SentimentAnalysisRegexPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# 各テキストブロックに対して、まず匿名化してから予測を行います
for entry in pii_data:
await model.predict(entry["text"])
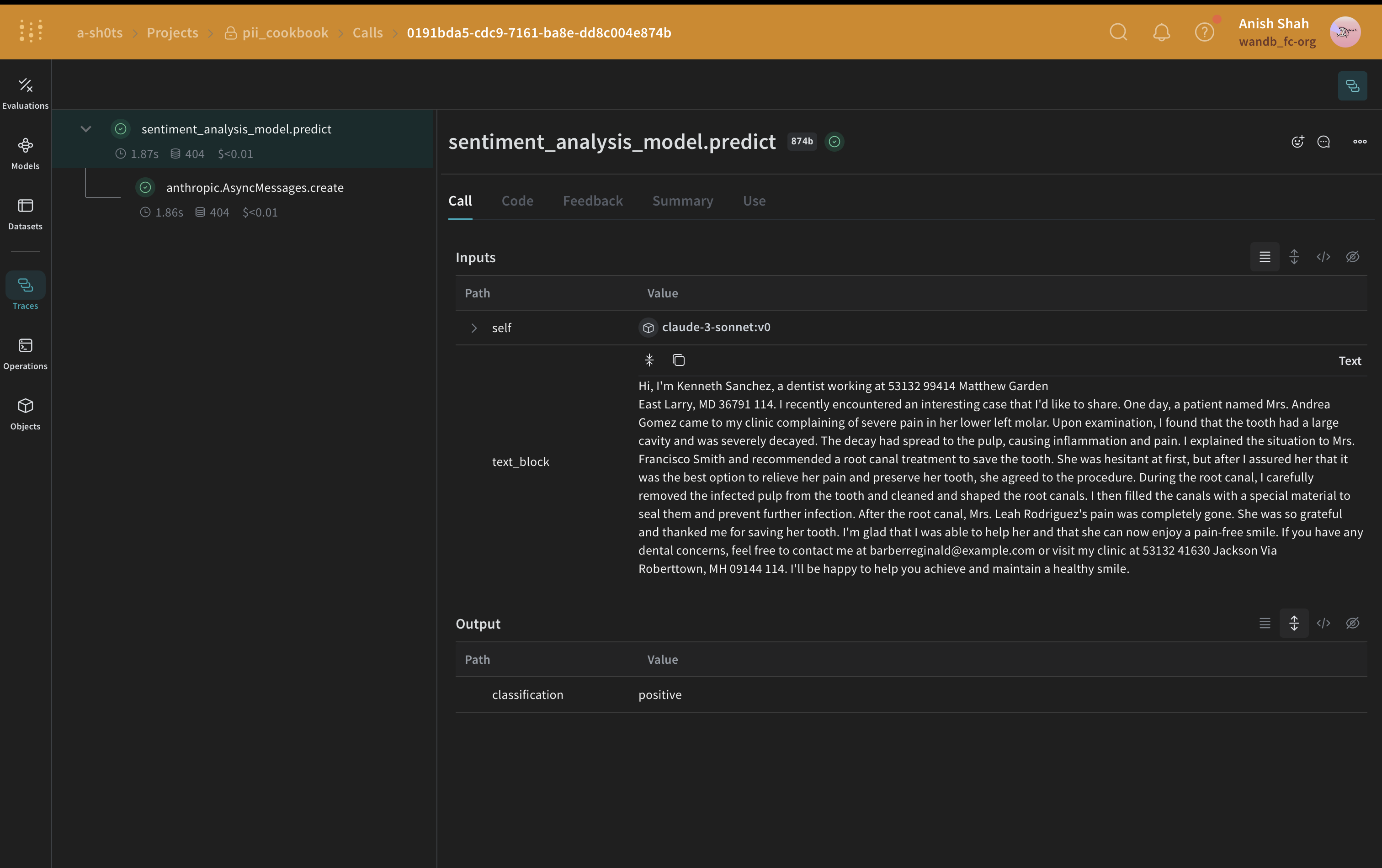
Presidio 墨消しメソッド
次に、Presidio を使用して元のテキストから PII データを特定して墨消しします。
from typing import Any
import weave
# モデルの予測用 Weave Op に対して、Presidio による墨消しを適用する入力後処理関数を定義します
def postprocess_inputs_presidio(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_presidio(inputs["text_block"])
return inputs
# Weave モデル / 予測関数
class SentimentAnalysisPresidioPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_presidio,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
# システムプロンプトを含む LLM モデルを作成します
model = SentimentAnalysisPresidioPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# 各テキストブロックに対して、まず匿名化してから予測を行います
for entry in pii_data:
await model.predict(entry["text"])
Faker と Presidio による置換メソッド
この例では、Faker を使用して匿名化された置換用 PII データを生成し、Presidio を使用して元のテキスト内の PII データを特定して置換します。
from typing import Any
import weave
# モデルの予測用 Weave Op に対して、Faker による匿名化と Presidio による墨消しを適用する入力後処理関数を定義します
faker = MyFaker()
def postprocess_inputs_faker(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = faker.redact_and_anonymize_with_faker(inputs["text_block"])
return inputs
# Weave モデル / 予測関数
class SentimentAnalysisFakerPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_faker,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
# システムプロンプトを含む LLM モデルを作成します
model = SentimentAnalysisFakerPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# 各テキストブロックに対して、まず匿名化してから予測を行います
for entry in pii_data:
await model.predict(entry["text"])
autopatch_settings メソッド
以下の例では、初期化時に anthropic の postprocess_inputs を postprocess_inputs_regex() 関数に設定しています。postprocess_inputs_regex 関数は、メソッド 1: 正規表現を使用したフィルタリング で定義された redact_with_regex メソッドを適用します。これにより、すべての anthropic モデルへの入力すべてに対して redact_with_regex が適用されるようになります。
from typing import Any
import weave
client = weave.init(
...,
autopatch_settings={
"anthropic": {
"op_settings": {
"postprocess_inputs": postprocess_inputs_regex,
}
}
},
)
# モデルの予測用 Weave Op に対して、正規表現による墨消しを適用する入力後処理関数を定義します
def postprocess_inputs_regex(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_regex(inputs["text_block"])
return inputs
# Weave モデル / 予測関数
class SentimentAnalysisRegexPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
# システムプロンプトを含む LLM モデルを作成します
model = SentimentAnalysisRegexPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# 各テキストブロックに対して、まず匿名化してから予測を行います
for entry in pii_data:
await model.predict(entry["text"])
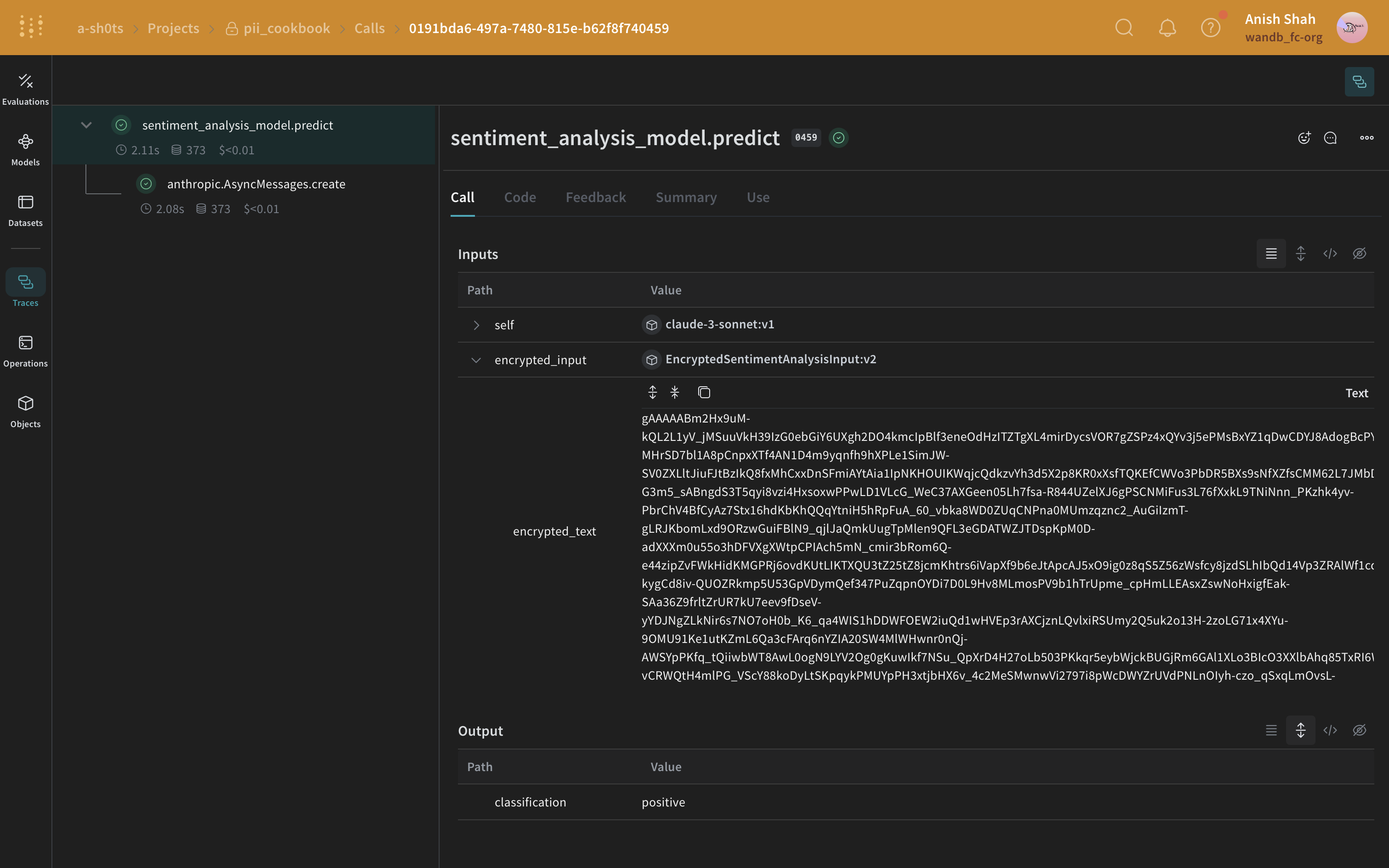
(オプション) データの暗号化
PII の匿名化に加えて、cryptography ライブラリの Fernet 対称暗号を使用してデータを暗号化することで、セキュリティレイヤーを追加できます。このアプローチにより、匿名化されたデータが傍受されたとしても、暗号化キーなしでは読み取れないことが保証されます。
import os
from cryptography.fernet import Fernet
from pydantic import BaseModel, ValidationInfo, model_validator
def get_fernet_key():
# 環境変数にキーが存在するか確認
key = os.environ.get('FERNET_KEY')
if key is None:
# キーが存在しない場合は新しく生成
key = Fernet.generate_key()
# 環境変数にキーを保存
os.environ['FERNET_KEY'] = key.decode()
else:
# キーが存在する場合はバイト形式であることを確認
key = key.encode()
return key
cipher_suite = Fernet(get_fernet_key())
class EncryptedSentimentAnalysisInput(BaseModel):
encrypted_text: str = None
@model_validator(mode="before")
def encrypt_fields(cls, values):
if "text" in values and values["text"] is not None:
values["encrypted_text"] = cipher_suite.encrypt(values["text"].encode()).decode()
del values["text"]
return values
@property
def text(self):
if self.encrypted_text:
return cipher_suite.decrypt(self.encrypted_text.encode()).decode()
return None
@text.setter
def text(self, value):
self.encrypted_text = cipher_suite.encrypt(str(value).encode()).decode()
@classmethod
def encrypt(cls, text: str):
return cls(text=text)
def decrypt(self):
return self.text
# 新しい EncryptedSentimentAnalysisInput を使用するように修正された sentiment_analysis_model
class sentiment_analysis_model(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op()
async def predict(self, encrypted_input: EncryptedSentimentAnalysisInput) -> dict:
client = AsyncAnthropic()
decrypted_text = encrypted_input.decrypt() # カスタムクラスを使用してテキストを復号します
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{ "role": "user",
"content":[
{
"type": "text",
"text": decrypted_text
}
]
}
]
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
model = sentiment_analysis_model(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt="You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option[\"positive\", \"negative\", \"neutral\"]. Your answer should one word in json format dict where the key is classification.",
temperature=0
)
for entry in pii_data:
encrypted_input = EncryptedSentimentAnalysisInput.encrypt(entry["text"])
await model.predict(encrypted_input)