이 가이드에서는 PyTorch와 MNIST 데이터를 사용하여 training 과정 동안 모델의 prediction을 추적, 시각화 및 비교하는 방법을 다룹니다. 다음 내용을 배우게 됩니다:Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-weave-caching.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
- 모델 training 또는 평가 중에
wandb.Table()에 metrics, 이미지, 텍스트 등을 log 하는 방법 - 이러한 테이블을 확인, 정렬, 필터링, 그룹화, 조인, 대화형 쿼리 및 탐색하는 방법
- 특정 이미지, 하이퍼파라미터/모델 버전 또는 타임스텝에 따라 동적으로 모델 prediction 또는 결과를 비교하는 방법
Examples
특정 이미지에 대한 예측 점수 비교
실시간 예시: training 1 에포크 vs 5 에포크 후의 예측 비교 →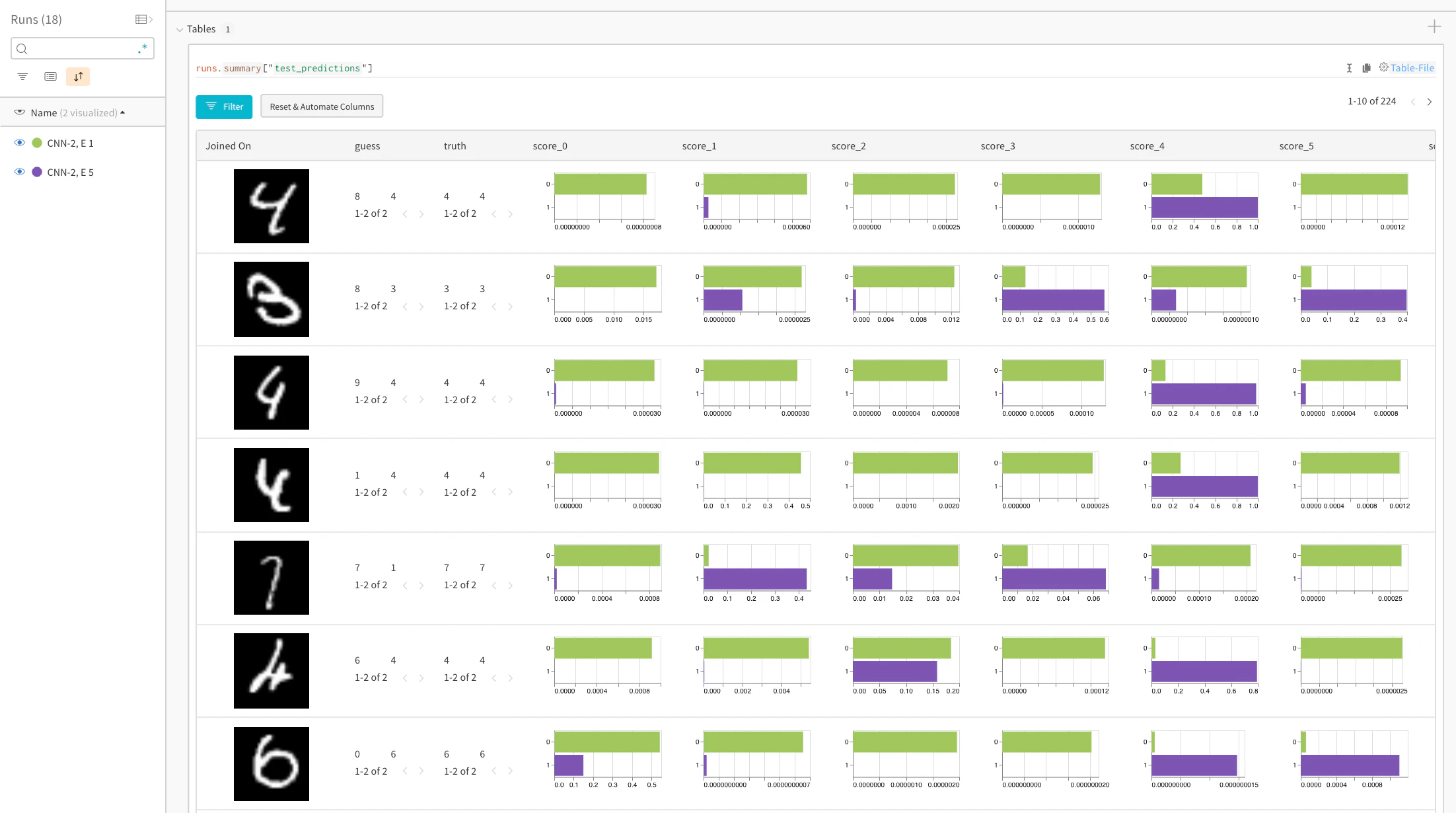
시간에 따른 주요 오류에 집중
실시간 예시 → 전체 테스트 데이터에서 잘못된 예측(“guess” != “truth”로 필터링)을 확인하세요. 1 에포크 training 후에는 229개의 잘못된 추측이 있었지만, 5 에포크 후에는 98개로 줄어든 것을 확인할 수 있습니다.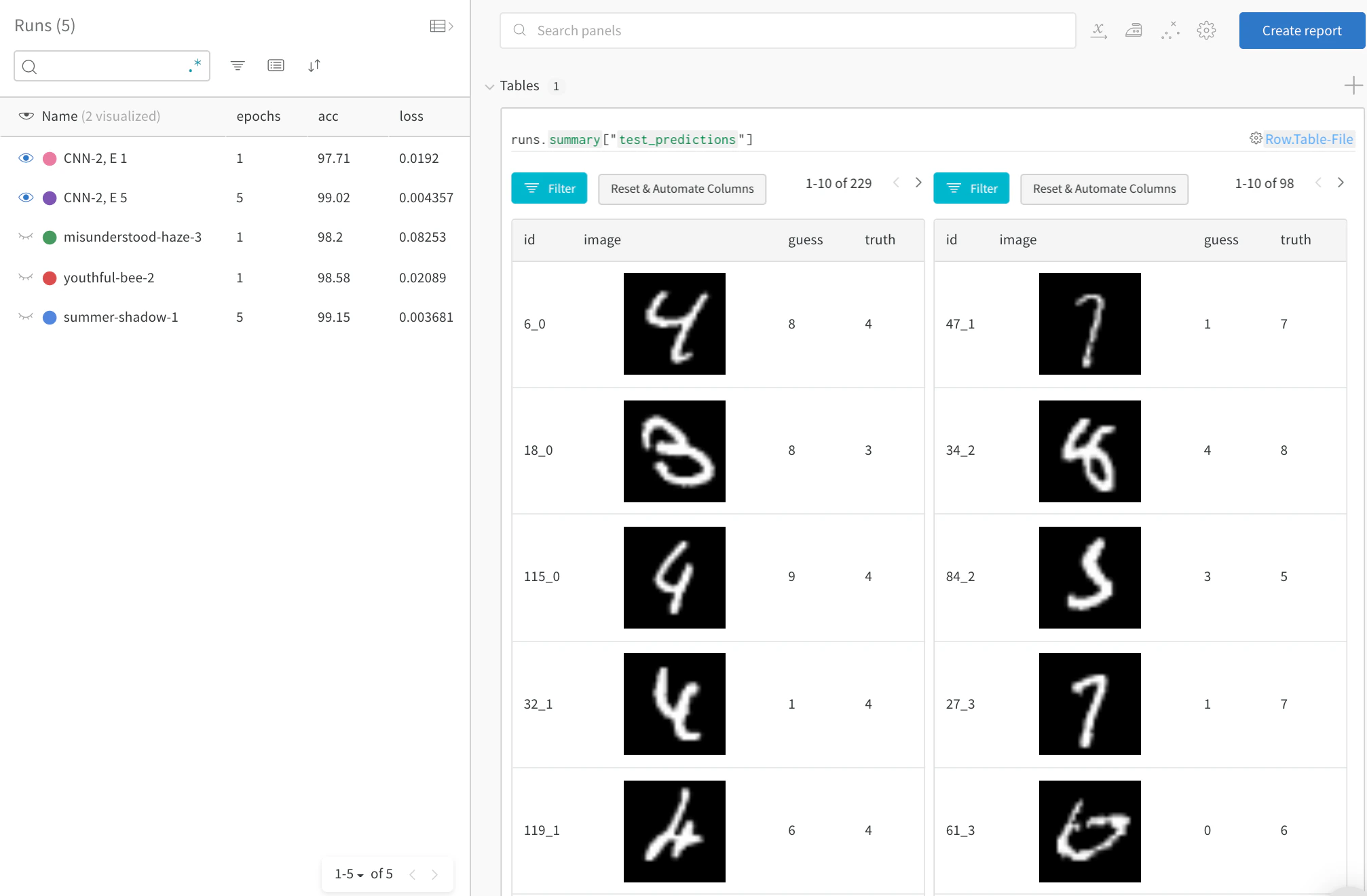
모델 성능 비교 및 패턴 찾기
실시간 예시에서 자세한 내용 보기 → 정답을 필터링한 다음, 추측(guess)별로 그룹화하여 오분류된 이미지의 예시와 실제 레이블의 기본 분포를 두 모델을 나란히 놓고 비교해 보세요. 왼쪽은 레이어 크기와 학습률이 2배인 모델 변형이고, 오른쪽은 베이스라인입니다. 베이스라인이 각 추측 클래스에 대해 약간 더 많은 실수를 하는 것을 알 수 있습니다.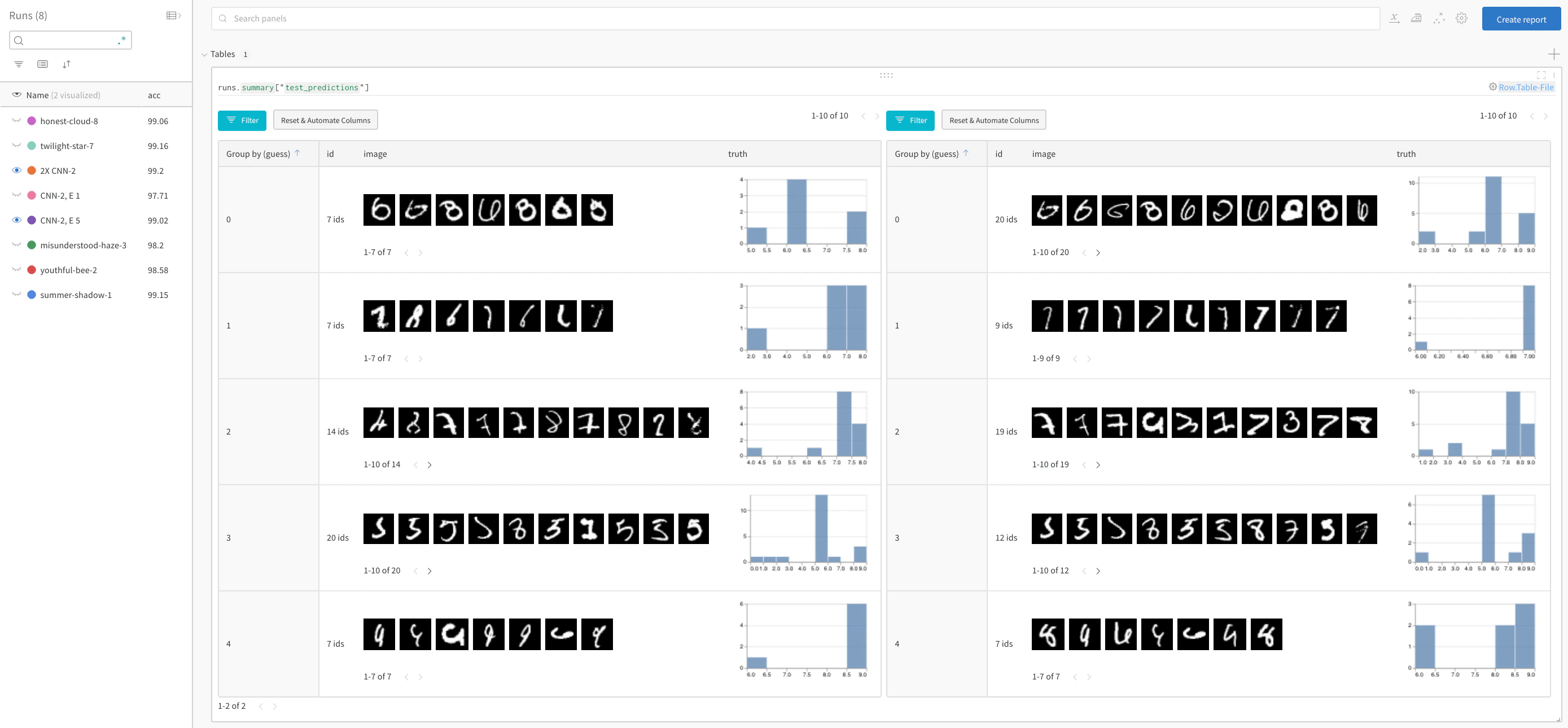
가입 또는 로그인
브라우저에서 진행 중인 Experiments를 확인하고 상호작용하려면 W&B에 가입하거나 로그인하세요. 이 예시에서는 편리한 호스팅 환경인 Google Colab을 사용하지만, 어디서든 트레이닝 스크립트를 실행하고 W&B의 experiment tracking 툴로 metrics를 시각화할 수 있습니다.0. Setup
PyTorch를 사용하여 의존성을 설치하고, MNIST를 다운로드하고, training 및 테스트 데이터셋을 생성합니다.1. 모델 및 training 일정 정의
- 실행할 에포크 수를 설정합니다. 각 에포크는 training 단계와 검증(테스트) 단계로 구성됩니다. 선택적으로 테스트 단계당 log 할 데이터 양을 설정합니다. 여기서는 데모를 단순화하기 위해 시각화할 배치 수와 배치당 이미지 수를 낮게 설정했습니다.
- 간단한 컨볼루션 신경망을 정의합니다 (pytorch-tutorial 코드 참조).
- PyTorch를 사용하여 training 및 테스트 세트를 로드합니다.
2. training 실행 및 테스트 prediction 로그 기록
매 에포크마다 training 단계와 테스트 단계를 실행합니다. 각 테스트 단계에서 테스트 prediction을 저장할wandb.Table()을 생성합니다. 이는 브라우저에서 시각화하고, 동적으로 쿼리하고, 나란히 비교할 수 있습니다.