Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-weave-caching.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Weave は、主要な AI 企業の基盤モデルを統合 API を通じて提供する AWS の完全マネージド型サービスである Amazon Bedrock を介して行われた LLM 呼び出しを、自動的に追跡しログを記録します。
Amazon Bedrock から Weave に LLM 呼び出しをログ記録する方法は複数あります。weave.op を使用して Bedrock モデルへの呼び出しを追跡するための再利用可能なオペレーションを作成することも、Anthropic モデルを使用している場合は、Weave の Anthropic との組み込みインテグレーションを使用することもできます。
Traces
Weave は Bedrock API 呼び出しの トレース を自動的にキャプチャします。Weave を初期化し、クライアントをパッチした後は、通常通り Bedrock クライアントを使用できます。
import weave
import boto3
import json
from weave.integrations.bedrock.bedrock_sdk import patch_client
weave.init("my_bedrock_app")
# Bedrock クライアントの作成とパッチ適用
client = boto3.client("bedrock-runtime")
patch_client(client)
# 通常通りクライアントを使用
response = client.invoke_model(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 100,
"messages": [
{"role": "user", "content": "What is the capital of France?"}
]
}),
contentType='application/json',
accept='application/json'
)
response_dict = json.loads(response.get('body').read())
print(response_dict["content"][0]["text"])
converse API を使用する場合:
messages = [{"role": "user", "content": [{"text": "What is the capital of France?"}]}]
response = client.converse(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
system=[{"text": "You are a helpful AI assistant."}],
messages=messages,
inferenceConfig={"maxTokens": 100},
)
print(response["output"]["message"]["content"][0]["text"])
独自の op でラッピングする
@weave.op() デコレータを使用して、再利用可能なオペレーションを作成できます。以下は、 invoke_model と converse 両方の API を示す例です。
@weave.op
def call_model_invoke(
model_id: str,
prompt: str,
max_tokens: int = 100,
temperature: float = 0.7
) -> dict:
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"temperature": temperature,
"messages": [
{"role": "user", "content": prompt}
]
})
# クライアントの呼び出し
response = client.invoke_model(
modelId=model_id,
body=body,
contentType='application/json',
accept='application/json'
)
return json.loads(response.get('body').read())
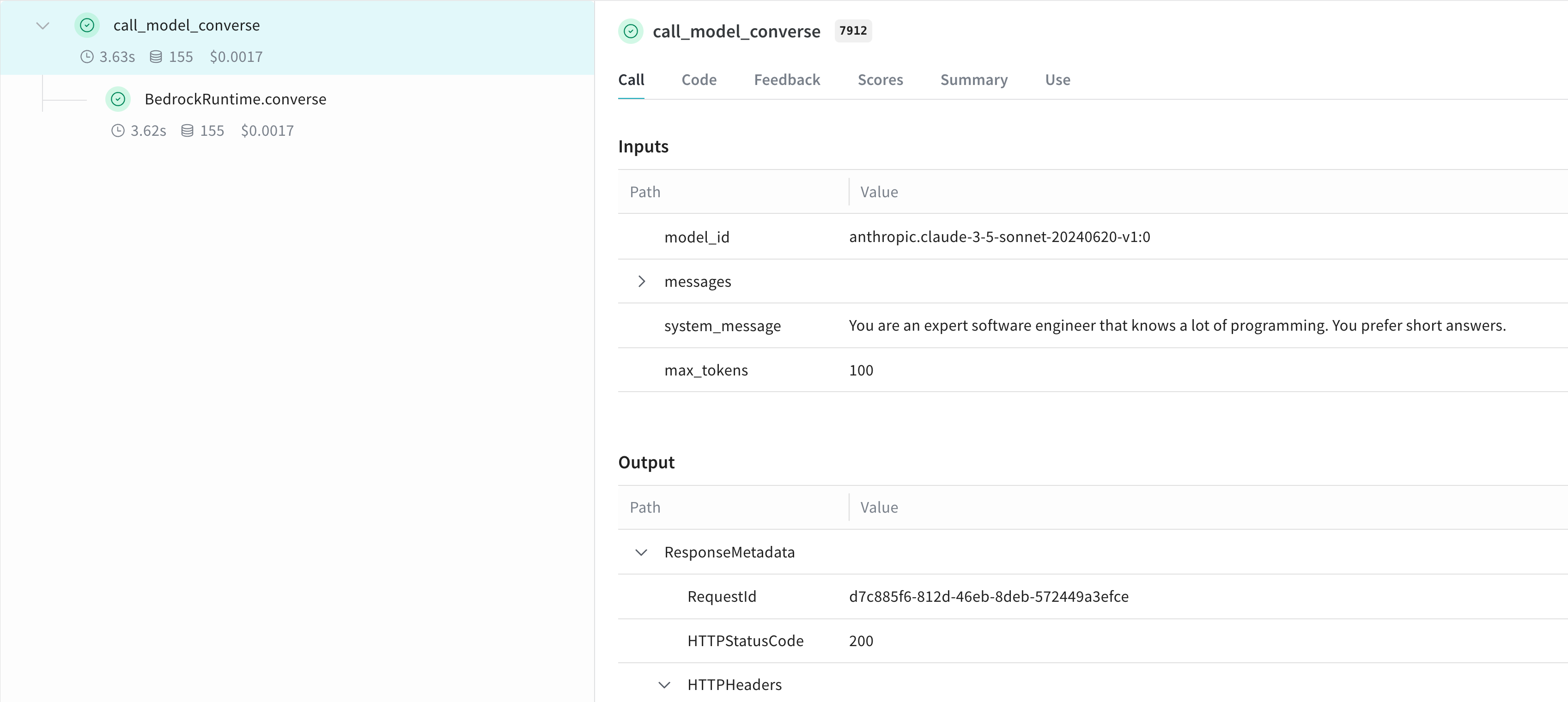
@weave.op
def call_model_converse(
model_id: str,
messages: str,
system_message: str,
max_tokens: int = 100,
) -> dict:
# converse API の呼び出し
response = client.converse(
modelId=model_id,
system=[{"text": system_message}],
messages=messages,
inferenceConfig={"maxTokens": max_tokens},
)
return response
実験を容易にするために Models を作成する
Weave Model を作成することで、 実験管理 をより適切に整理し、 パラメータ をキャプチャできます。以下は converse API を使用した例です。
class BedrockLLM(weave.Model):
model_id: str
max_tokens: int = 100
system_message: str = "You are a helpful AI assistant."
@weave.op
def predict(self, prompt: str) -> str:
# Bedrock の converse API を使用して応答を生成
messages = [{
"role": "user",
"content": [{"text": prompt}]
}]
response = client.converse(
modelId=self.model_id,
system=[{"text": self.system_message}],
messages=messages,
inferenceConfig={"maxTokens": self.max_tokens},
)
return response["output"]["message"]["content"][0]["text"]
# モデルの作成と使用
model = BedrockLLM(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
max_tokens=100,
system_message="You are an expert software engineer that knows a lot of programming. You prefer short answers."
)
result = model.predict("What is the best way to handle errors in Python?")
print(result)
詳細情報
Weave で Amazon Bedrock を使用する方法についてさらに詳しく知る
Weave Playground で Bedrock を試す
セットアップなしで Weave UI 内で Amazon Bedrock モデルを試してみたいですか? LLM Playground をお試しください。
Reports: Weave を使用した Bedrock 上の LLM によるテキスト要約の比較
Compare LLMs on Bedrock for text summarization with Weave レポート では、Bedrock と Weave を組み合わせて、要約タスクの LLM を評価および比較する方法を、コードサンプルを含めて説明しています。