Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-weave-caching.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
 Weave は、
Weave は、 weave.init() を呼び出した後、 LiteLLM を介して行われる LLM 呼び出しを自動的に追跡し、 ログ を記録します。
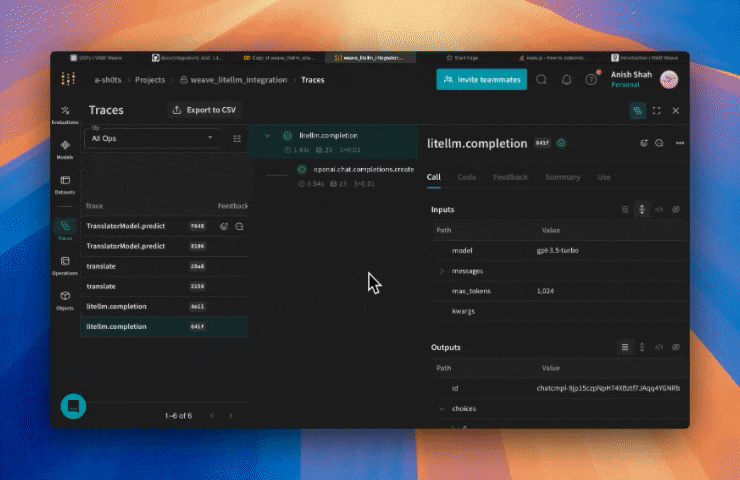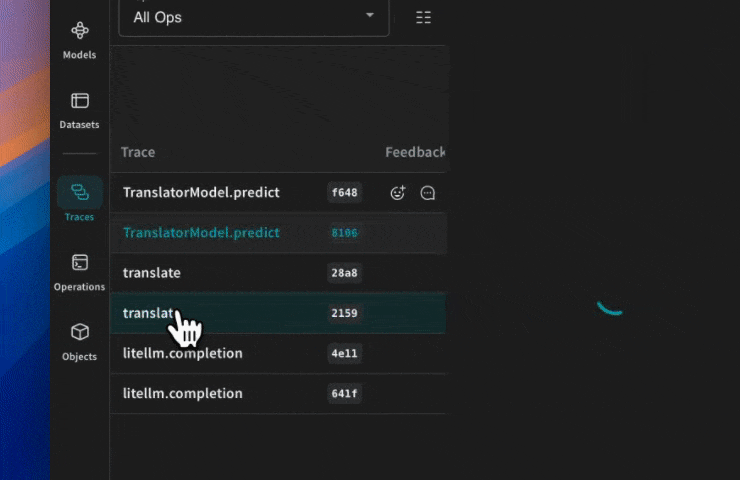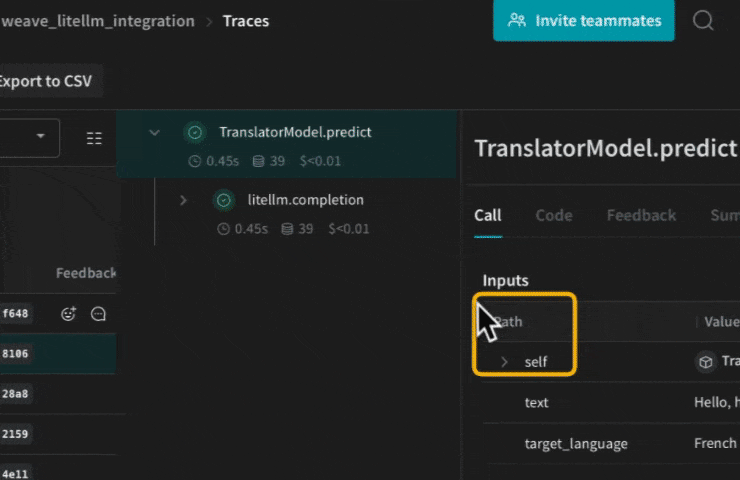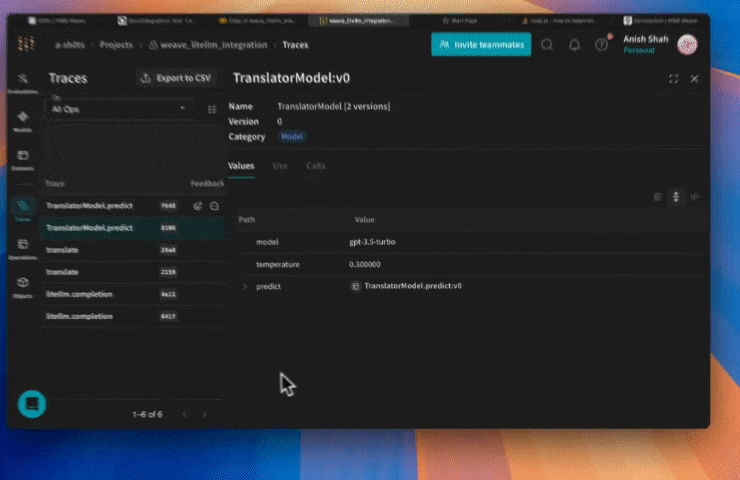
Traces
開発中および プロダクション の両方において、 LLM アプリケーション の トレース を中央の データベース に保存することは重要です。 これらの トレース は、 デバッグ や、 アプリケーション を改善するための データセット として活用できます。
注意: LiteLLM を使用する場合、 from litellm import completion ではなく、 import litellm を使用して ライブラリ をインポートし、 litellm.completion で補完機能を呼び出すようにしてください。 これにより、 すべての関数と パラメータ が正しく参照されます。
Weave は LiteLLM の トレース を自動的に取得します。 通常通り ライブラリ を使用できます。 まずは weave.init() を呼び出すことから始めましょう:
import litellm
import weave
# Weaveを初期化
weave.init("weave_litellm_integration")
openai_response = litellm.completion(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
max_tokens=1024
)
print(openai_response.choices[0].message.content)
claude_response = litellm.completion(
model="claude-3-5-sonnet-20240620",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
max_tokens=1024
)
print(claude_response.choices[0].message.content)
独自の op でラップする
Weave の op を使用すると、 実験 に伴い コード を自動的に バージョン管理 し、 入出力を取得することで、 結果 の再現性を高めることができます。 @weave.op() デコレータを付けた関数を作成し、 その中で LiteLLM の completion 関数を呼び出すだけで、 Weave が入出力を追跡します。 以下に例を示します:
import litellm
import weave
weave.init("weave_litellm_integration")
@weave.op()
def translate(text: str, target_language: str, model: str) -> str:
# LiteLLMを呼び出すopを作成
response = litellm.completion(
model=model,
messages=[{"role": "user", "content": f"Translate '{text}' to {target_language}"}],
max_tokens=1024
)
return response.choices[0].message.content
print(translate("Hello, how are you?", "French", "gpt-3.5-turbo"))
print(translate("Hello, how are you?", "Spanish", "claude-3-5-sonnet-20240620"))
実験を容易にするための Model の作成
多くの要素が動的に変化する状況では、 実験 の整理が難しくなります。 Model クラスを使用すると、 システムプロンプトや使用している モデル などの アプリケーション の 実験 詳細を取得し、 整理することができます。 これにより、 アプリケーション の異なる反復(イテレーション)の整理や比較が容易になります。
コード の バージョン管理 や入出力の取得に加えて、 Models は アプリケーション の 振る舞い を制御する構造化された パラメータ を取得するため、 どの パラメータ が最適であったかを簡単に見つけ出すことができます。 また、 Weave の Models は serve や Evaluations と併用することも可能です。
以下の例では、 異なる モデル や temperature(温度)を試すことができます:
import litellm
import weave
weave.init('weave_litellm_integration')
class TranslatorModel(weave.Model):
model: str
temperature: float
@weave.op()
def predict(self, text: str, target_language: str):
response = litellm.completion(
model=self.model,
messages=[
{"role": "system", "content": f"You are a translator. Translate the given text to {target_language}."},
{"role": "user", "content": text}
],
max_tokens=1024,
temperature=self.temperature
)
return response.choices[0].message.content
# 異なるモデルでインスタンスを作成
gpt_translator = TranslatorModel(model="gpt-3.5-turbo", temperature=0.3)
claude_translator = TranslatorModel(model="claude-3-5-sonnet-20240620", temperature=0.1)
# 翻訳に異なるモデルを使用
english_text = "Hello, how are you today?"
print("GPT-3.5 Translation to French:")
print(gpt_translator.predict(english_text, "French"))
print("\nClaude-3.5 Sonnet Translation to Spanish:")
print(claude_translator.predict(english_text, "Spanish"))
関数呼び出し (Function Calling)
LiteLLM は、 対応している モデル で関数呼び出しをサポートしています。 Weave はこれらの関数呼び出しを自動的に追跡します。
import litellm
import weave
weave.init("weave_litellm_integration")
response = litellm.completion(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
functions=[
{
"name": "translate",
"description": "Translate text to a specified language",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The text to translate",
},
"target_language": {
"type": "string",
"description": "The language to translate to",
}
},
"required": ["text", "target_language"],
},
},
],
)
print(response)