Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-weave-caching.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
 Weave 는
Weave 는 weave.init() 이 호출된 후 LiteLLM 을 통해 이루어지는 LLM 호출을 자동으로 추적하고 로그를 남깁니다.
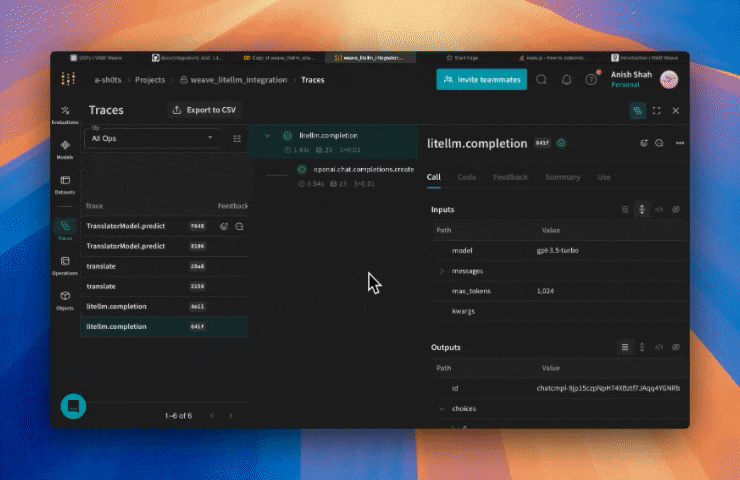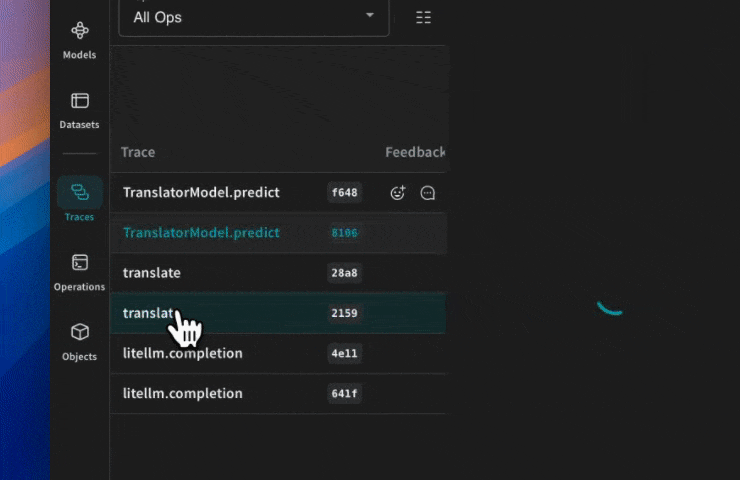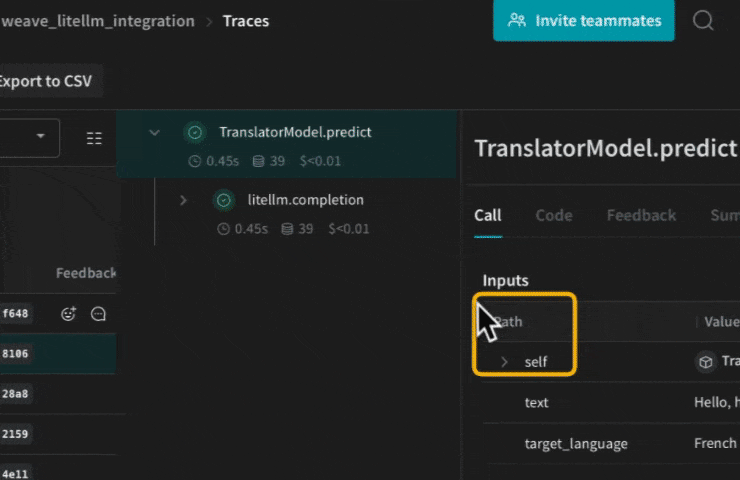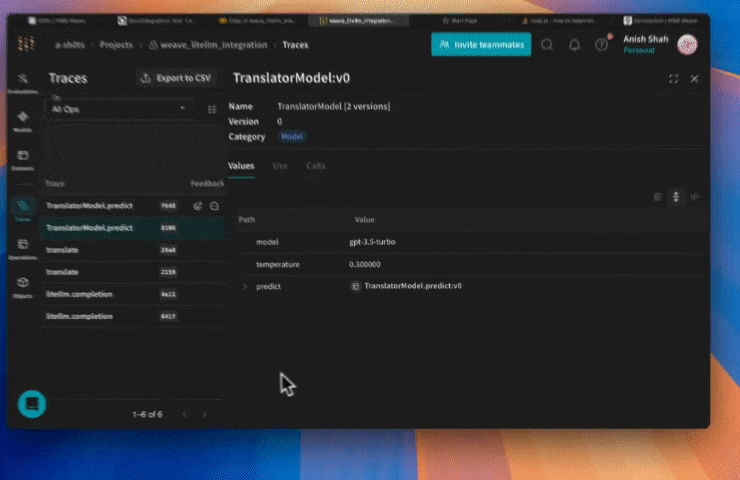
Traces
개발 및 프로덕션 단계 모두에서 LLM 애플리케이션의 트레이스를 중앙 데이터베이스에 저장하는 것이 중요합니다. 이러한 트레이스는 디버깅에 사용될 뿐만 아니라, 애플리케이션을 개선하는 데 도움이 되는 Datasets 으로 활용됩니다.
참고: LiteLLM 을 사용할 때는 from litellm import completion 대신 import litellm 으로 라이브러리를 임포트하고 litellm.completion 으로 completion 함수를 호출해야 합니다. 이를 통해 모든 함수와 파라미터가 올바르게 참조되도록 보장할 수 있습니다.
Weave 는 LiteLLM 에 대한 트레이스를 자동으로 캡처합니다. 평소처럼 라이브러리를 사용하되, 먼저 weave.init() 을 호출하여 시작하세요:
import litellm
import weave
weave.init("weave_litellm_integration")
openai_response = litellm.completion(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
max_tokens=1024
)
print(openai_response.choices[0].message.content)
claude_response = litellm.completion(
model="claude-3-5-sonnet-20240620",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
max_tokens=1024
)
print(claude_response.choices[0].message.content)
자신만의 ops 로 래핑하기
Weave ops 는 실험 중에 코드를 자동으로 버전 관리하여 결과의 재현성을 높이고, 입력과 출력을 캡처합니다. LiteLLM 의 completion 함수를 호출하는 함수를 만들고 @weave.op() 데코레이터를 추가하기만 하면 Weave 가 입력과 출력을 자동으로 추적해 줍니다. 예시는 다음과 같습니다:
import litellm
import weave
weave.init("weave_litellm_integration")
@weave.op()
def translate(text: str, target_language: str, model: str) -> str:
# LiteLLM의 completion 함수 호출
response = litellm.completion(
model=model,
messages=[{"role": "user", "content": f"Translate '{text}' to {target_language}"}],
max_tokens=1024
)
return response.choices[0].message.content
print(translate("Hello, how are you?", "French", "gpt-3.5-turbo"))
print(translate("Hello, how are you?", "Spanish", "claude-3-5-sonnet-20240620"))
더 쉬운 실험을 위해 Model 만들기
많은 요소가 복합적으로 작용할 때 실험을 체계화하는 것은 어렵습니다. Model 클래스를 사용하면 시스템 프롬프트나 사용 중인 모델과 같은 앱의 실험적 세부 정보를 캡처하고 정리할 수 있습니다. 이는 앱의 다양한 반복(iteration)을 구성하고 비교하는 데 도움이 됩니다.
Models 는 코드 버전 관리 및 입출력 캡처 외에도, 애플리케이션의 행동을 제어하는 구조화된 파라미터를 캡처하므로 어떤 파라미터가 가장 효과적이었는지 쉽게 찾을 수 있습니다. 또한 Weave Models 를 serve 및 Evaluations 와 함께 사용할 수도 있습니다.
아래 예시에서는 다양한 모델과 온도를 사용하여 실험할 수 있습니다:
import litellm
import weave
weave.init('weave_litellm_integration')
class TranslatorModel(weave.Model):
model: str
temperature: float
@weave.op()
def predict(self, text: str, target_language: str):
response = litellm.completion(
model=self.model,
messages=[
{"role": "system", "content": f"You are a translator. Translate the given text to {target_language}."},
{"role": "user", "content": text}
],
max_tokens=1024,
temperature=self.temperature
)
return response.choices[0].message.content
# 다양한 모델로 인스턴스 생성
gpt_translator = TranslatorModel(model="gpt-3.5-turbo", temperature=0.3)
claude_translator = TranslatorModel(model="claude-3-5-sonnet-20240620", temperature=0.1)
# 번역을 위해 다른 모델 사용
english_text = "Hello, how are you today?"
print("GPT-3.5 Translation to French:")
print(gpt_translator.predict(english_text, "French"))
print("\nClaude-3.5 Sonnet Translation to Spanish:")
print(claude_translator.predict(english_text, "Spanish"))
Function Calling
LiteLLM 은 호환되는 모델에 대해 function calling 을 지원합니다. Weave 는 이러한 함수 호출을 자동으로 추적합니다.
import litellm
import weave
weave.init("weave_litellm_integration")
response = litellm.completion(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Translate 'Hello, how are you?' to French"}],
functions=[
{
"name": "translate",
"description": "Translate text to a specified language",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The text to translate",
},
"target_language": {
"type": "string",
"description": "The language to translate to",
}
},
"required": ["text", "target_language"],
},
},
],
)
print(response)